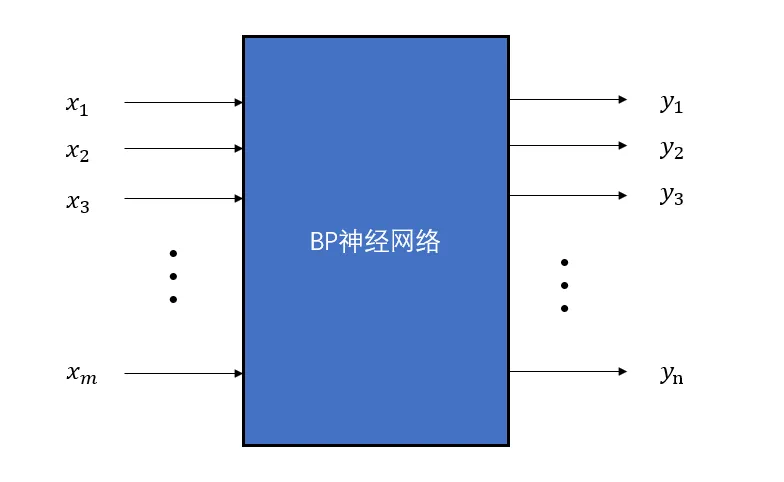
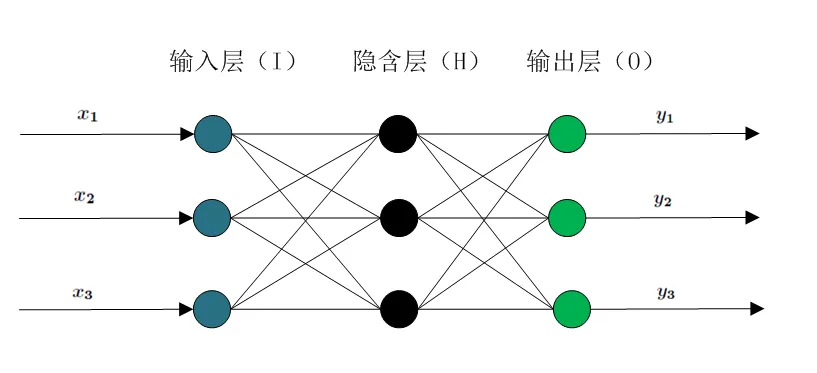
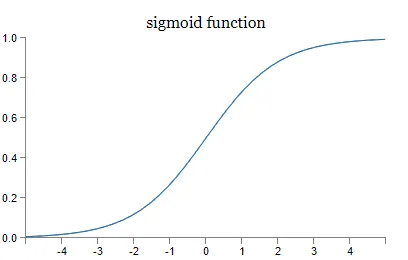
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
| import cv2 as cv
import numpy as np
import math
sigma=1.5
def add_zeros(img,edge):
shape=img.shape
temp=np.zeros((shape[0]+2*edge,shape[1]+2*edge))
for i in range(shape[0]):
for j in range(shape[1]):
temp[i+edge][j+edge]=img[i][j][0]
return temp
def f(x,y):
return 1/(math.pi*sigma**2)*math.exp(-(x**2+y**2)/(2*sigma**2))
def gauss(n):
mid=n//2
filt=np.zeros((n,n))
for i in range(n):
for j in range(n):
filt[i][j]=f(i-mid,j-mid)/f(-mid,-mid)
return filt.astype(np.uint8)
def gauss_filter(img,n):
filt=gauss(n)
con=1/np.sum(filt)
shape=img.shape
temp=add_zeros(img,n//2)
result=np.zeros((shape[0],shape[1],1))
for i in range(shape[0]):
for j in range(shape[1]):
tmp=0
for k in range(n):
for l in range(n):
tmp+=filt[k][l]*temp[i+k][j+l]
result[i][j][0]=con*tmp
return result.astype(np.uint8)
def unsharp_mask(img,n,is_mask=0):
shape=img.shape
new_img=np.zeros((shape[0],shape[1],1))
for i in range(shape[0]):
for j in range(shape[1]):
new_img[i][j][0]=img[i][j][0]
mask=new_img-gauss_filter(img,n)
for i in range(shape[0]):
for j in range(shape[1]):
if i==0 or j==0 or i==shape[0]-1 or j==shape[1]-1:
mask[i][j][0]=0
result=new_img+mask
result=result-np.min(result)
result=result/np.max(result)*255
mask=mask-np.min(mask)
mask=mask/np.max(mask)*255
if is_mask:
return mask.astype(np.uint8)
return result.astype(np.uint8)
sobelx=[[-1,0,1],[-2,0,2],[-1,0,1]]
sobely=[[-1,-2,-1],[0,0,0],[1,2,1]]
laplace4=[[0,-1,0],[-1,4,-1],[0,-1,0]]
laplace8=[[-1,-1,-1],[-1,8,-1],[-1,-1,-1]]
def filt_3(img,filt):
shape=img.shape
temp=add_zeros(img,1)
result=np.zeros((shape[0],shape[1],1))
for i in range(shape[0]):
for j in range(shape[1]):
tmp=0
for k in range(3):
for l in range(3):
tmp+=filt[k][l]*temp[i+k][j+l]
result[i][j][0]=tmp
return result
def laplace_edge(img,filt):
tmp=filt_3(img,filt)
tmp=tmp-np.min(tmp)
shape=tmp.shape
for i in range(shape[0]):
for j in range (shape[1]):
if i==0 or j==0 or i==shape[0]-1 or j==shape[1]-1:
tmp[i][j][0]=0
tmp=tmp/np.max(tmp)*255
return tmp.astype(np.uint8)
def laplace(img,filt):
tmp=filt_3(img,filt)
shape=img.shape
result=np.zeros((shape[0],shape[1]))
for i in range(shape[0]):
for j in range(shape[1]):
result[i][j]=tmp[i][j][0]+img[i][j][0]
if i==0 or j==0 or i==shape[0]-1 or j==shape[1]-1:
result[i][j]=0
result-=np.min(result)
result=result/np.max(result)*255
return result.astype(np.uint8)
def sobel(img):
shape=img.shape
sobx=filt_3(img,sobelx)
soby=filt_3(img,sobely)
result=np.zeros((shape[0],shape[1]))
for i in range(shape[0]):
for j in range(shape[1]):
if i==0 or j==0 or i==shape[0]-1 or j==shape[1]-1:
result[i][j]=0
else:
result[i][j]=math.sqrt(sobx[i][j][0]**2+soby[i][j][0]**2)
result=result/np.max(result)*255
return result.astype(np.uint8)
def canny(img,n=3):
de=[[1,0,-1,0],[1,1,-1,-1],[0,1,0,-1],[-1,1,1,-1]]
shape=img.shape
tmp=gauss_filter(img,n)
sobx=filt_3(tmp,sobelx)
soby=filt_3(tmp,sobely)
weight,angle,result=np.zeros((shape[0],shape[1])),np.zeros((shape[0],shape[1])),np.zeros((shape[0],shape[1]))
angle=angle.astype(np.int)
for i in range(shape[0]):
for j in range(shape[1]):
weight[i][j]=math.sqrt(sobx[i][j][0]**2+soby[i][j][0]**2)
if sobx[i][j][0]:
angle[i][j]=round((math.atan(soby[i][j][0]/sobx[i][j][0])/(math.pi/4)-0.5))%4
for i in range(shape[0]-2):
for j in range(shape[1]-2):
tmp_i,tmp_j=i+1,j+1
if weight[tmp_i][tmp_j]<=weight[tmp_i+de[angle[tmp_i][tmp_j]][0]][tmp_j+de[angle[tmp_i][tmp_j]][1]] and weight[tmp_i][tmp_j]<=weight[tmp_i+de[angle[tmp_i][tmp_j]][2]][tmp_j+de[angle[tmp_i][tmp_j]][3]]:
result[tmp_i][tmp_j]=0
else:
result[tmp_i][tmp_j]=weight[tmp_i][tmp_j]
result=result/np.max(result)*255
mean=np.mean(img)
for i in range(shape[0]):
for j in range(shape[1]):
if result[i][j]<100:
result[i][j]=0
return result.astype(np.uint8)
filename=["test3_corrupt.pgm","test4.tif"]
for i in filename:
img=cv.imread(i)
cv.imwrite(i+"_mask.bmp",unsharp_mask(img,3,1))
cv.imwrite(i+"_unsharp_mask.bmp",unsharp_mask(img,3))
cv.imwrite(i+"_sobel.bmp",sobel(img))
cv.imwrite(i+"_canny.bmp",canny(img,3))
cv.imwrite(i+"laplace4_edge.bmp",laplace_edge(img,laplace4))
cv.imwrite(i+"laplace8_edge.bmp",laplace_edge(img,laplace8))
|