Crawling all anime data from Bilibili and conducting data analysis.
This is an automatically translated post by LLM. The original post is in Chinese. If you find any translation errors, please leave a comment to help me improve the translation. Thanks!
Introduction
Bilibili (referred to as B station) has a large number of anime copyrights, with a total of 3161 as of now. Each anime can be found with its play count, follow count, barrage count, and other playback data. In addition, each anime has its corresponding tags (such as "comic adaptation", "hot-blooded", "comedy"). This project aims to analyze the relationship between anime playback data and anime tags, and it is also a data analysis project that uses APriori frequent itemset mining for analysis.
GitHub address: https://github.com/KezhiAdore/BilibiliAnimeData_Analysis
Gitee address: https://gitee.com/KezhiAdore/BilibiliAnimeData_Analysis
Data Collection
First, we need to obtain all the data we need, which are all the
anime playback information and tag information on B station. We use web
crawlers to crawl the data, and here we use scrapy in
Python to write the crawler to crawl the data.
Page Analysis
First, go to the anime index page on B station
Click on a certain anime on this page to enter its details page
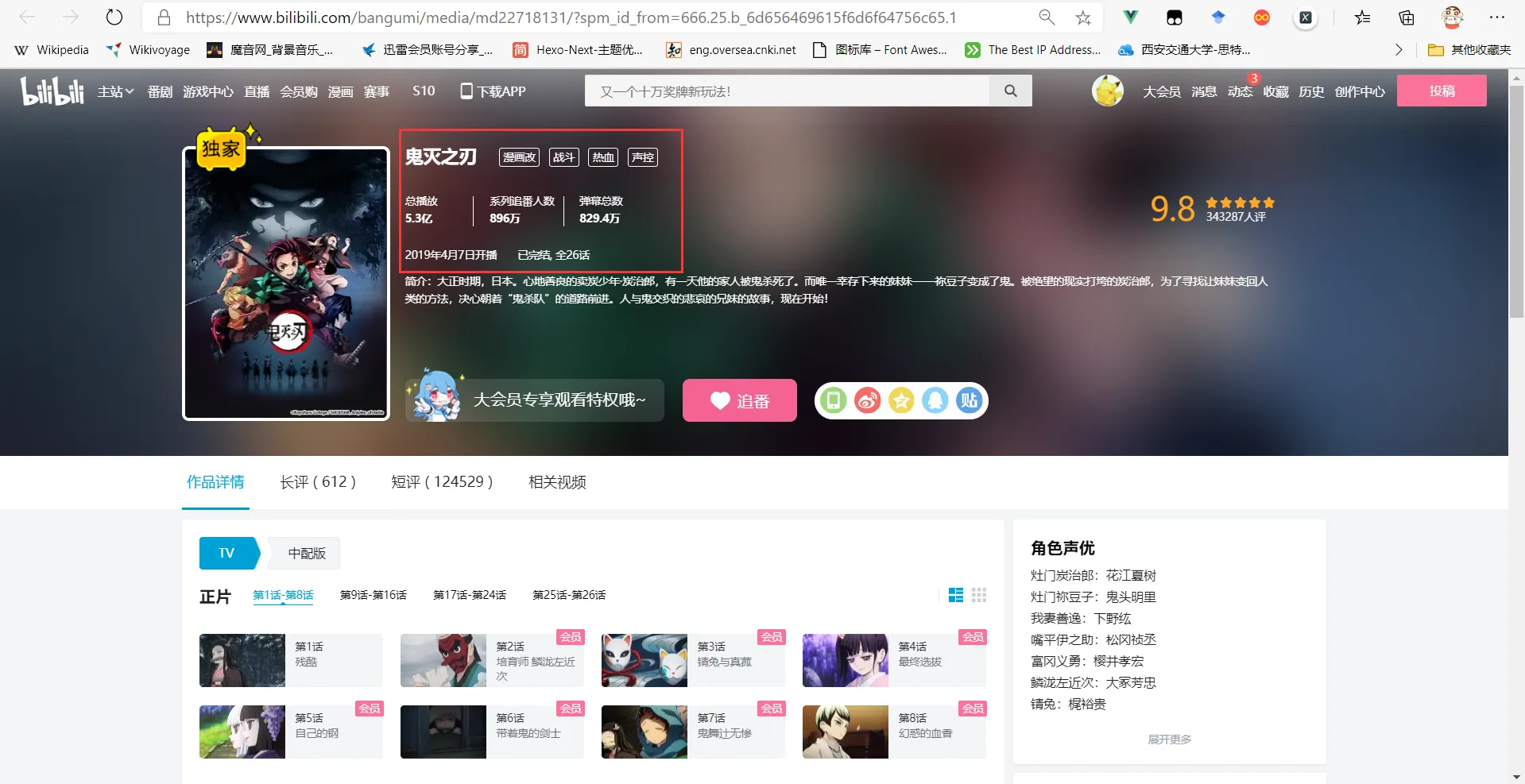
You can see that the required anime playback data and anime tags are available on this page.
Analyze the HTML of this page to find the xpath path where the data is located, taking tags as an example:
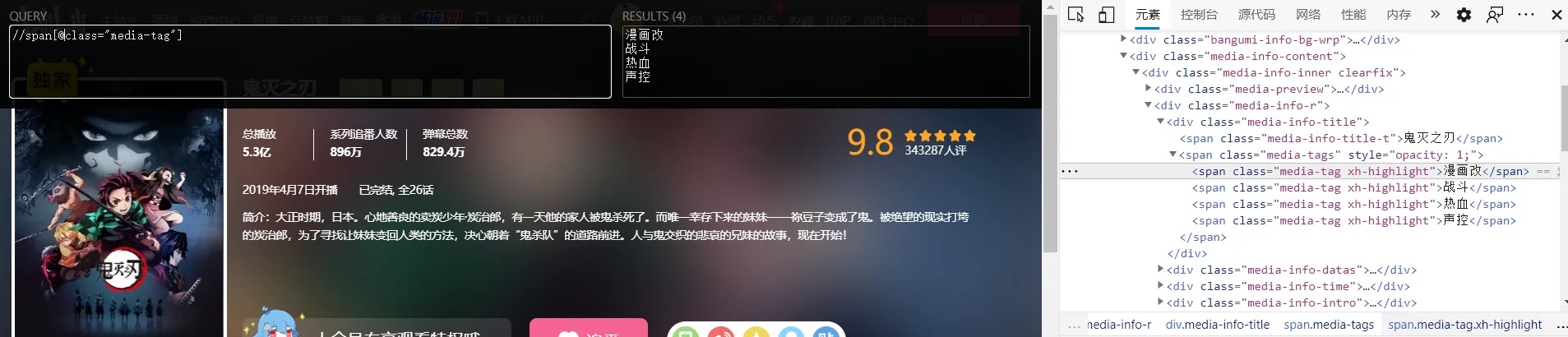
The xpath paths corresponding to all the data are:
1 | Tags: //span[@class="media-tag"] |
So far, we can loop through all the anime list pages, enter the details page from this page, and parse each anime details page to save the data. However, there is a problem at this point. After crawling the anime list page, the corresponding place in the web page data is:
Directly accessing this page cannot obtain detailed anime list information. Therefore, we need to analyze the files received by the page and find the anime list information obtained by this page.
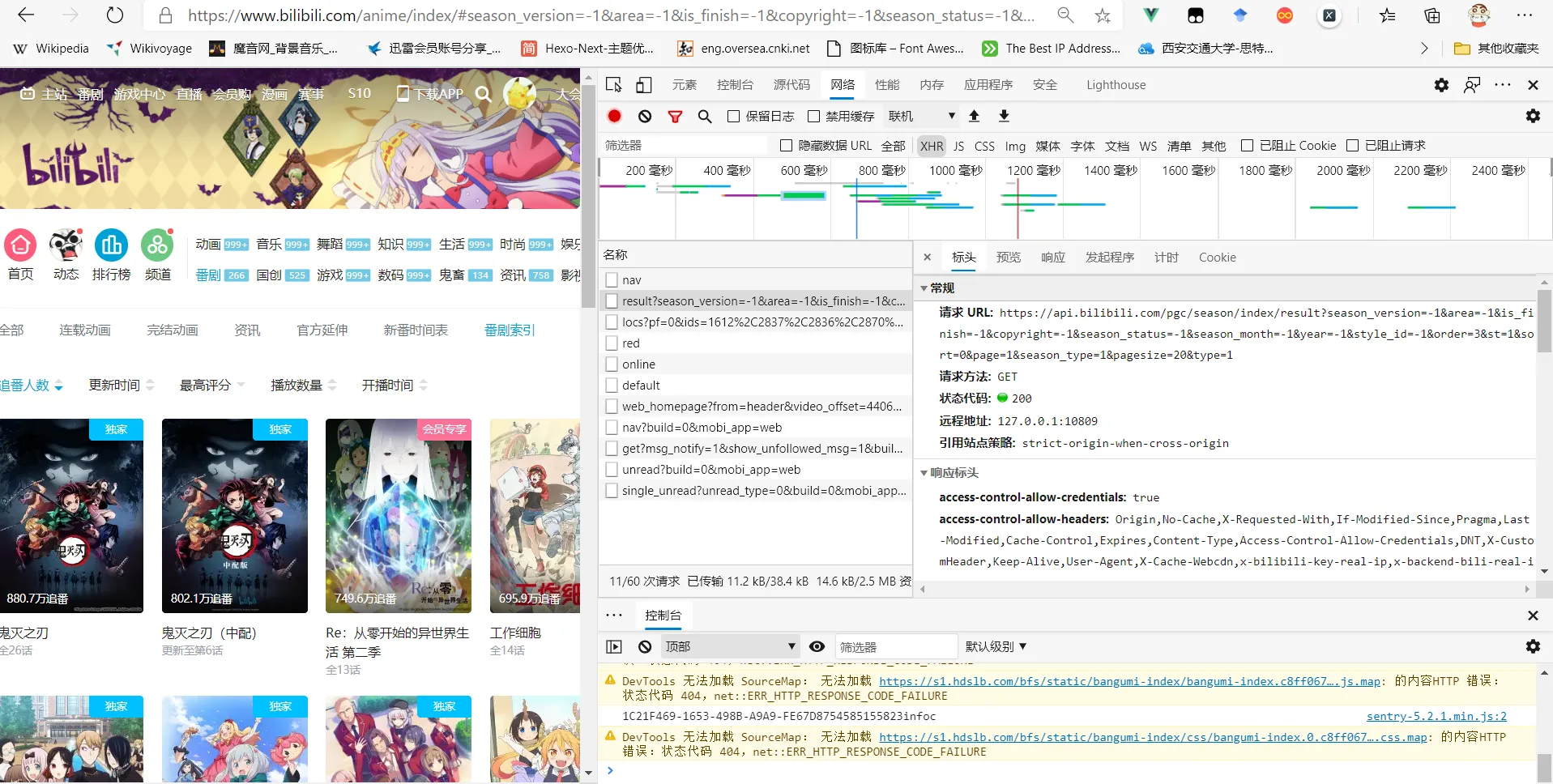
Accessing this URL will get the following information:
Analyzing this API URL, it can be found that the page=1
controls the page number information, and by changing this information,
different anime list pages can be accessed.
1 | https://api.bilibili.com/pgc/season/index/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&order=3&st=1&sort=0&page=1&season_type=1&pagesize=20&type=1 |
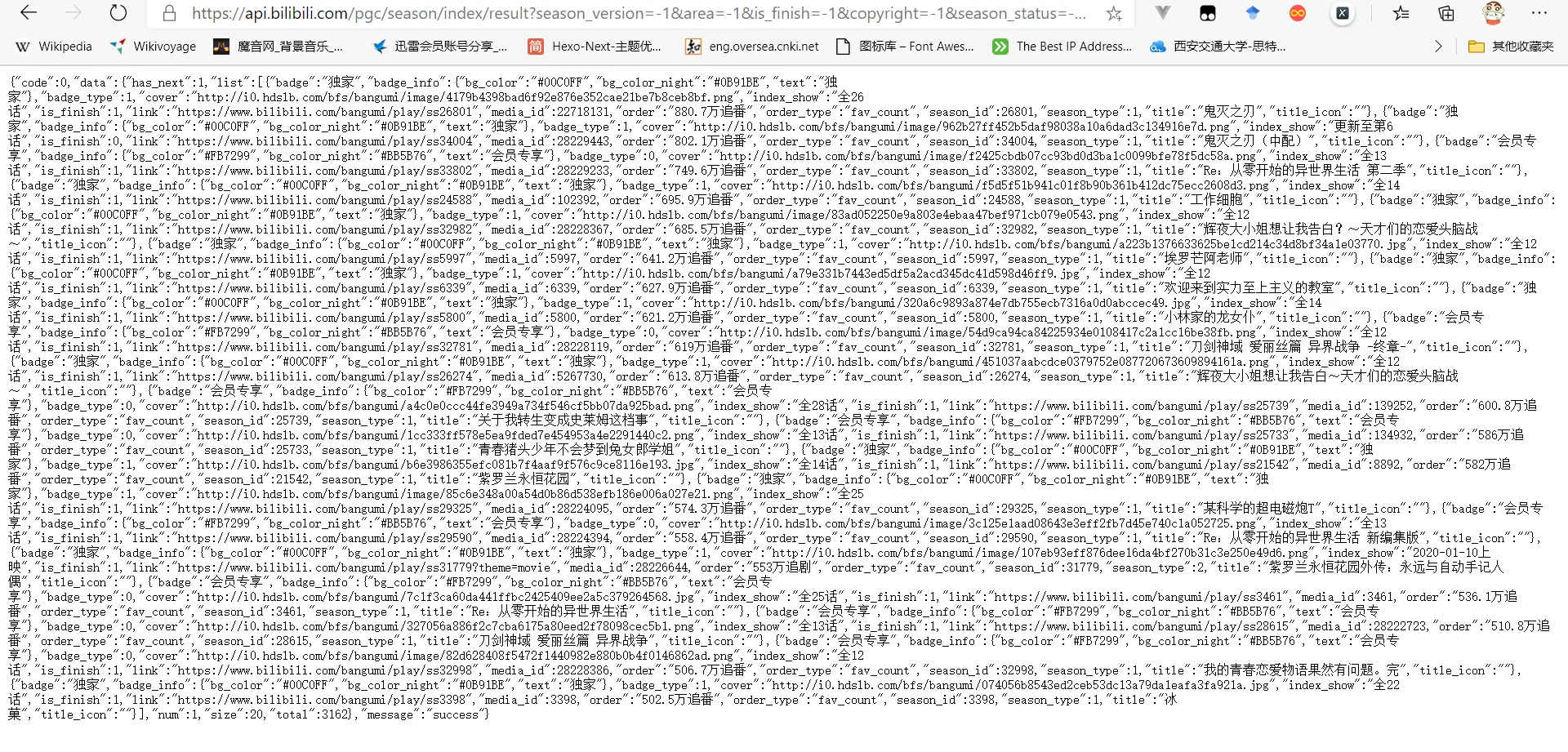
The information obtained from this page is a JSON file, and the information format is as follows:
By comparing with the URL of the anime details page https://www.bilibili.com/bangumi/media/md22718131,
it can be found that the media_id data in the JSON file is
the identifier of each anime details page. Therefore, the logic of
crawling information is basically established.
- Access the initial API page (page=1), parse its content, and get the
media_idof all anime on this page. - Use
media_idto construct the link to access the anime details page, crawl this page for parsing, and get the data of an anime. - Access the next API page and repeat the above steps.
Spider Construction
First, initialize the spider
1 | scrapy startproject anime_data |
The file tree is as follows
Open items.py and create the data object that needs to
be saved
1 | import scrapy |
Then open the newly created anime.py, access the page,
parse it, and save the data as follows
1 | import scrapy |
Data Analysis
Data Cleaning and Filtering
The collected data cannot be used directly and needs to be cleaned and filtered, which can be divided into two steps:
- Remove data without tag information
- Convert quantity information in the data to numbers (e.g., convert "10,000" to "10000")
For the first step, since the data volume is small, you can quickly complete it using the filtering function in Excel.
For the second step, write the following function to convert the data:
1 | # Convert text data to numbers |
Frequent Itemset Mining using Apriori Algorithm
- Itemsets and Datasets
Let the set of all items appearing in the data be \(U=\left\{I_1,I_2,...,I_n\right\}\), and let the data to be mined for frequent itemsets be the set of transactions in the database \(D\). The data in \(D\) are itemsets, and each itemset \(T\subseteq U\).
- Association Rules (Support and Confidence)
Let \(A\) and \(B\) be two itemsets, \(A\subset U,B\subset U, A\neq \emptyset,B\neq \emptyset,A\cap B=\emptyset\).
An association rule is in the form of \(A\Rightarrow B\), and its support in the transaction set \(D\) is denoted as \(s\), where \(s\) is the percentage of transactions in the transaction set \(D\) that contain \(A\cup B\).
Its confidence in the transaction set \(D\) is denoted as \(c\), which is the percentage of transactions in the transaction set \(D\) that contain \(B\) among the transactions that contain \(A\), i.e., \(P(A|B)\). \[ c=P(B|A)=\frac{P(A\cup B)}{P(A)}=\frac{support(A\cup B)}{support(A)}=\frac{support\text{_}count(A\cup B)}{support\text{_}count(A)} \]
- Frequent Itemsets
When mining frequent itemsets, set the minimum confidence and minimum support, and rules that satisfy both the minimum support and minimum confidence are called strong rules, and itemsets that satisfy such strong rules are called frequent itemsets.
Association Rules
Each anime has a certain number of tags to roughly
describe its content. The tags used to describe the same anime are
usually descriptions in different dimensions. Taking "Miss Kobayashi's
Dragon Maid" as an example, its tags are
[moe, comedy, daily life, comic adaptation], and the four
tags describe four different characteristics of this anime. By analyzing
the anime tag data on B station, find the combinations of
tags with the highest relevance.
Algorithm Flow
Data set: The tag data set of all anime, each data is
the tag of an anime
The flow of the Apriori algorithm is as follows:
Construct 1-itemsets -> Count the frequency of 1-itemsets -> Calculate support and confidence -> Pruning -> Frequent 1-itemsets
Construct k-itemsets using k-1-itemsets -> Count the frequency of k-itemsets -> Calculate support and confidence -> Pruning -> Frequent k-itemsets
Repeat step 2 until there are no itemsets that meet the strong rules
Programming Implementation
First, read the processed data and convert the tag data,
which is originally a string, into a list:
1 | filepath='data_processed.csv' |
The data in tags is a string rather than a list, such
as: "恋爱,推理,校园,日常", which needs to be converted into
a list. The implementation is as follows:
1 | # Convert comma-separated strings to lists using commas as separators |
Construct k-itemsets using k-1-itemsets:
1 | # Apriori algorithm connection step, implemented step by step |
Determine the inclusion relationship between lists:
1 | # Determine if l2 is included in l1 |
Pruning operation:
1 | # Prune using min_sup and min_conf, that is, minimum support and minimum confidence, L_last is the frequent k-1-itemset |
Apriori algorithm main body:
1 | def Apriori(data,min_sup,min_conf): |
K-means Clustering Algorithm
Algorithm Introduction
K-means is an unsupervised clustering algorithm. The algorithm is simple and easy to implement, but it may produce empty clusters or converge to local optima.
The algorithm flow is as follows:
- Randomly select k points from the samples as initial centroids.
- Calculate the distance from each sample to these k centroids and assign the sample to the cluster whose centroid is closest to it.
- Recalculate the centroids of each cluster.
- Repeat steps 2 and 3 until the centroids do not change.
Data Mapping
Use K-means to cluster the anime based on the three-dimensional
coordinates formed by the three types of data
[play count, follow count, barrage count]. However, the
values of these three data range from thousands to billions, so they
cannot be used directly. Apply a logarithmic function to compress the
data: \[
[x,y,z]=[ln\ x,ln\ y,ln\ z]
\] After the logarithmic transformation, in order to ensure that
each type of data has the same range to ensure that they have the same
weight, normalize the data: \[
x=\frac{x-min}{max-min}
\] The implementation code is as follows:
1 | def trans_data(data): |
K-means Programming Implementation
In clustering, the distance measure used is the Euclidean distance, which is: \[ distance=\sqrt{(x_{1}-y_{1})^2+...+(x_{i}-y_{i})^2+...+(x_{n}-y_{n})^2} \] The implementation code is as follows:
1 | def distance(point1,point2): |
- Randomly select k points as centroids
1 | shape=np.array(dire).shape |
- Cluster all the data
1 | def get_category(dire,k,k_center): |
- Calculate new centroids and repeat
1 | # Maximum number of iterations |
The complete K-means algorithm main body is as follows:
1 | def k_means(dire,k): |
Algorithm Results and Evaluation
To visually see the clustering results, plot the clustered points in three-dimensional space, using different colors to represent different categories.
The plotting function is as follows:
2
3
4
5
6
7
8
9
10
11
12
k,k_categories,dire=k_result['k'],k_result['k_categories'],k_result['dire']
for i in range(k):
x,y,z=[],[],[]
for index in k_categories[i]:
x.append(dire[index][0])
y.append(dire[index][1])
z.append(dire[index][2])
fig = plt.gcf()
ax = fig.gca(projection='3d')
ax.scatter(x,y,z)
plt.show()
The clustering results are as follows:
|
|
|
|
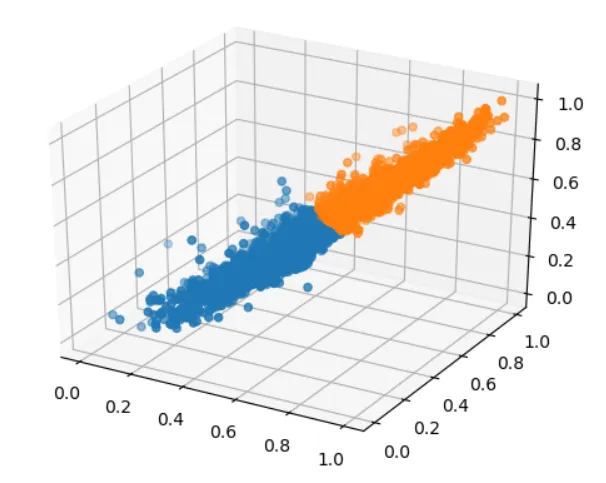
|
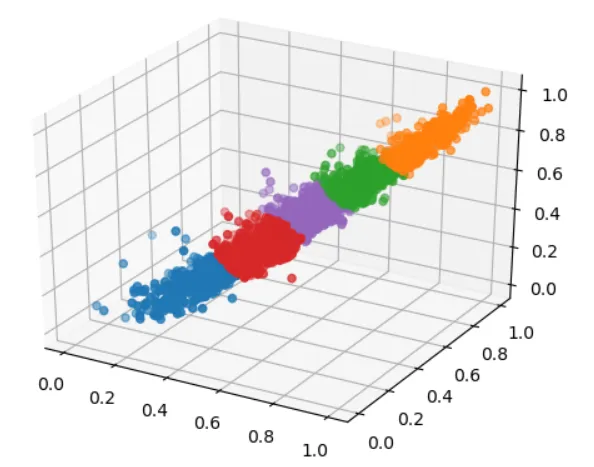
|
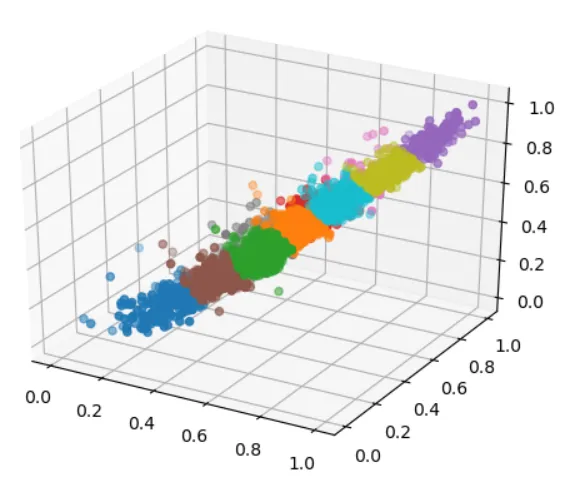
|
To evaluate the clustering effect, select the Davies-Bouldin Index (DBI) to evaluate the clustering effect. The algorithm and method of DBI are as follows:
- Suppose there are k clusters, and the center point of each cluster is \(u_i\), and the points in the cluster are represented by \(x_{ij}\)
- Calculate the average distance within each cluster \(\mu_i\), which is the average distance from all points in the cluster to the cluster center
- Calculate the distance between centroids \(d(u_i,u_j)\)
- Calculate DBI:
\[ DB=\frac1k\sum_{i=1}^k\mathop{max}\limits_{i\neq j}(\frac{\mu_i+\mu_j}{d(u_i,u_j)}) \]
The implementation code is as follows:
1 | def dbi(k_result): |
The evaluation results of clustering when k=2-10 are as follows:
| k | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| DBI | 0.7028 | 0.7851 | 0.8324 | 0.9075 | 0.9267 | 0.9927 | 0.9242 | 0.9123 | 0.8849 |
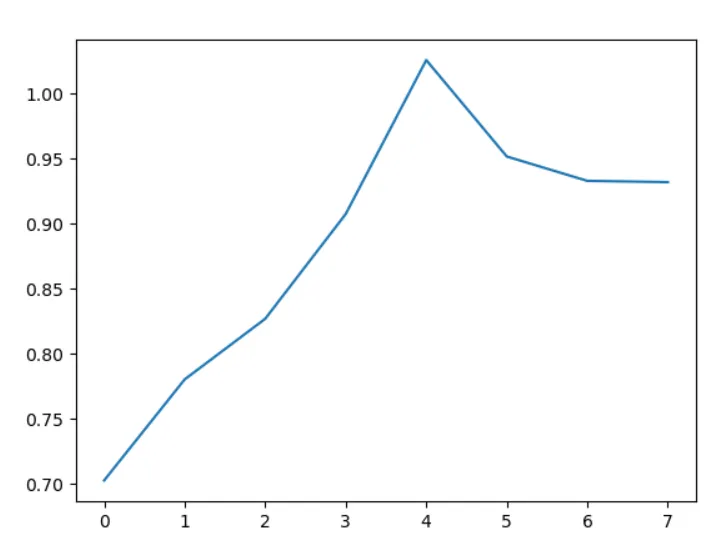
The evaluation results of k=2-50 are as follows:
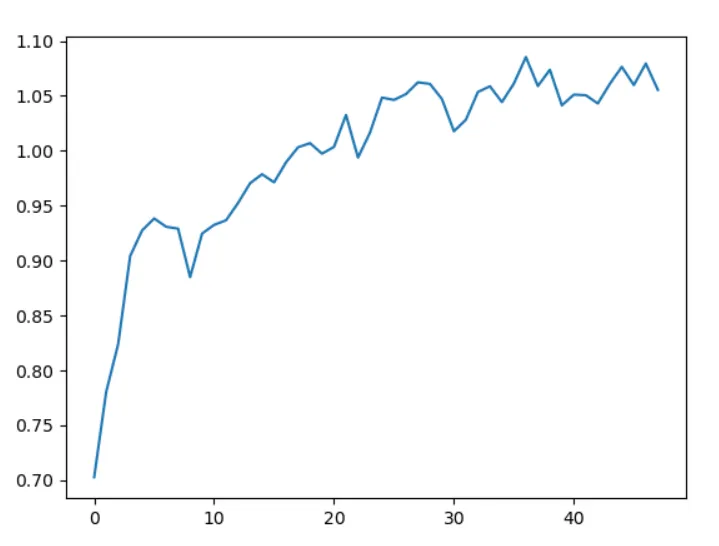
From the above results, it can be seen that the clustering effect is best when k=2 or 3. Analyzing from the data used and the characteristics of the k-means algorithm, the k-means algorithm uses Euclidean distance for clustering, and the regions divided are spherical. From the three-dimensional image, the data used does not have a clear boundary to separate the data. When k=2 or 3, each cluster is concentrated in a sphere, showing better clustering results. As k continues to increase, the clustering effect gradually deteriorates due to the influence of isolated points around the data.