王者荣耀目标检测--Yolov5实现
智能体对战目标检测
手动标注数据集及视频分割程序下载见文章末。

识别演示视频:
1. 引言
1.1 问题背景
强化学习过去在博弈领域取得了很高的成就。如在围棋上打败人类的Alpha Go (Silver, D. et.al., 2016),经过数天自博弈即可在多种棋类游戏上战胜顶尖人类的Alpha Zero (Silver, D. et.al., 2018),以及在星际争霸游戏中打败人类的Alpha Star (Vinyals, O. et.al., 2019)。王者荣耀中达到职业选手水平的觉悟Ai (Wu, B., 2019)。强化学习的发展使得人工智能在游戏对战领域取得了越来越好的成绩。
但同时,上述智能体解决的问题中,要么环境较为简单(如围棋,象棋等棋牌类游戏),要么在智能体决策的过程时的输入经过了特定的处理。如Alpha Star的输入中包含了很多无法直接从屏幕上观测到的数据 (Vinyals, O. et.al., 2019)。而要训练出更加具有通用性的智能体,就需要环境的输入更加一般,通用。计算机视觉成为了一种很好的选择。
在大量的智能体对战场景中,视觉信息是最重要,包含信息量最丰富的信息。如在游戏中,画面信息是玩家获取到的主要信息;在棋牌博弈中,场上的局势和对手的表情信息等都是视觉信息;在军事对战环境中,大量传感器捕获到的都是类视觉信息。因此,如何将视觉信息转换为环境描述信息发送给智能体进行决策具有很强的现实意义。
其中,目标检测是视觉信息转换中很重要的一环。不论是在虚拟游戏环境中,还是在现实环境中,确认地形,友方位置,地方位置都是重中之重。这对智能体之后的动作决策至关重要。因此,本文从游戏对战场景中的目标检测出发,训练一个可以在游戏环境中检测敌我双方智能体单位,中立单位以及环境特征的神经网络模型,实现对场景中的重要主体的检测。
2. 方法原理
本文使用 YoloV5(Ultralytics) 来构建目标检测网络,对游戏场景中的主体进行识别。
Yolov5 的网络结构如下图所示:
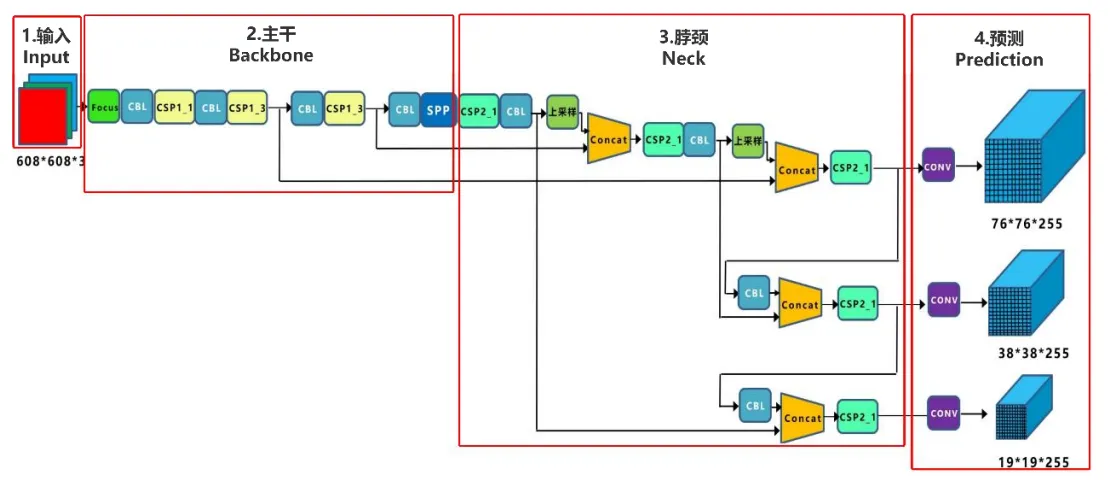
从Yolov5的网络结构图,可以看出,还是分为输入端 Input、主干 Backbone、脖颈 Neck、预测 Prediction四个部分。接下来从这四个部分分别介绍该网络
2.1 输入端 Input
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
2.2 主干 Backbone
2.2.1 Focus结构
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。其网络结构如下:
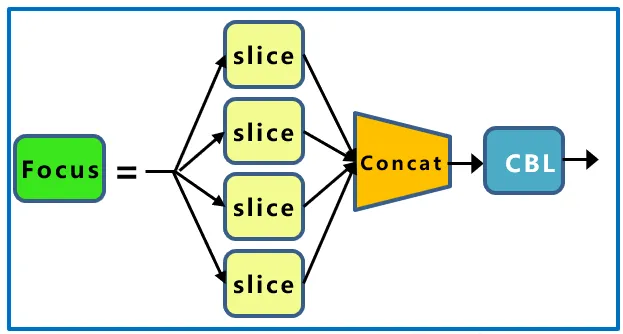
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:

2.2.2 CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。其在保证准确 度的前提下有效减少了计算量。其网络结构如下图所示
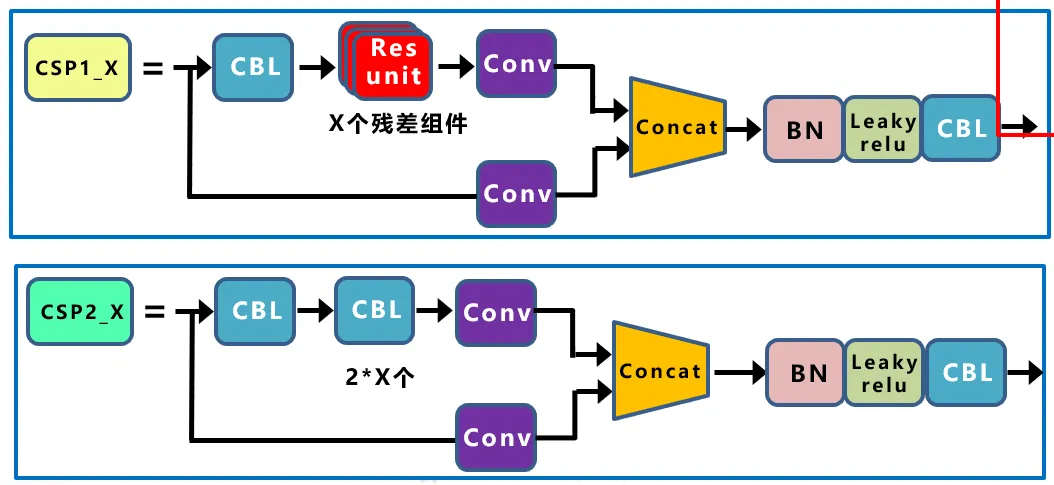
其中,CBL结构和Resunit 结构如下图所示:
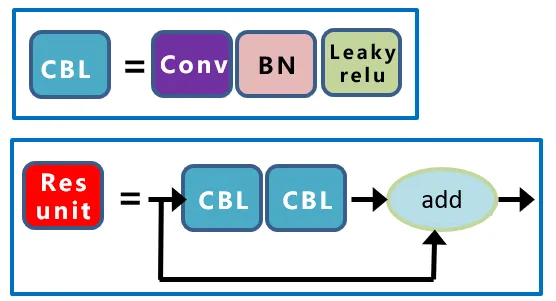
2.2.3 SPP结构
SPP 模块借鉴了 SPPNet(Spatial Pyramid Pooling Network),由四个并行的分 支组成,采用多种不同大小的卷积核对图片进行卷积,然后将卷积结果进行融合, 有效扩大了模型的感受野,使得模型可以处理图片大小差距较大的情况。其网络结构如下图所示:
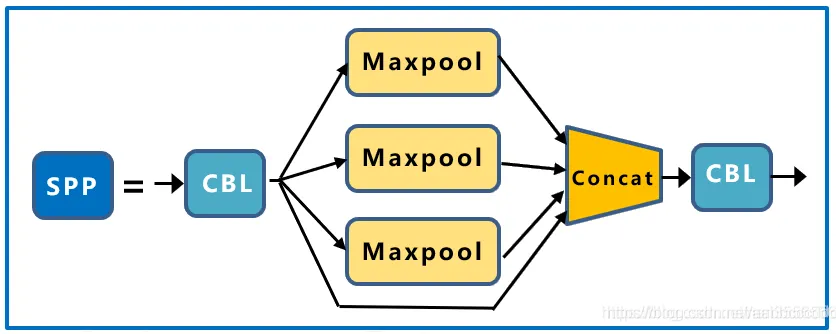
2.3 脖颈 Neck
Yolov5 的 Neck 部分采用了 PANet 结构,Neck 主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
PANet 结构是在FPN的基础上引入了 Bottom-up path augmentation 结构。FPN主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果。Bottom-up path augmentation结构可以充分利用网络浅特征进行分割,网络浅层特征信息对于目标检测非常重要,因为目标检测是像素级别的分类浅层特征多是边缘形状等特征。PANet 在 FPN 的基础上加了一个自底向上方向的增强,使得顶层 feature map 也可以享受到底层带来的丰富的位置信息,从而提升了大物体的检测效果。
此外,Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
2.4 预测 Prediction
2.4.1 Bounding box损失函数
Yolov5中采用GIOU_Loss做Bounding box的损失函数。GIOU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合 度。
2.4.2 加权非极大抑制NMS
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要NMS操作。Yolov5中采用加权NMS的方式来剔除边框,与传统的非极大值抑制相 比,加权非极大值抑制并非直接将边框与阈值相比较来进行筛选,而是根据网络预测结果的置信度进行加权得到最终的目标检测矩形框。
3. 数据集及评测指标
3.1 数据集准备
本文采用手动标注的游戏画面数据集,游戏画面采用王者荣耀匹配赛的一局游戏中的随机抽帧获得,一共标注8类主体,其类别和标签如下表所示:
| 类别 | 英雄 | 小兵 | 野怪 | 防御塔 | 草丛 | 龙 | 红蓝buff | 血包 |
|---|---|---|---|---|---|---|---|---|
| 标注 | hero | dogface | monster | tower | grass | dragon | buff | blood |
其中,每一种类别的标注样本数量如下表所示:
| 类别 | 英雄 | 小兵 | 野怪 | 防御塔 | 草丛 | 龙 | 红蓝buff | 血包 |
|---|---|---|---|---|---|---|---|---|
| 训练集 | 319 | 101 | 83 | 58 | 353 | 48 | 30 | 6 |
| 验证集 | 90 | 32 | 12 | 18 | 91 | 10 | 11 | 1 |
3.2 评测指标
模型的评价指标主要由两部分构成,预测准确率(Prediction)和召回率(Recall)。其中: \[ Prediction=\frac{TP}{TP+TN}\\ Recall=\frac{TP}{TP+FP} \] 在目标检测中,通常用各类别的平均准确率(Average Precision,AP)来衡量算 法的性能,它的值由查准率(Precision)和查全率(Recall)共同决定,根据式 算出的 Recall 和 Precision 可以作出一条 P-R 曲线,该曲线 与 X 轴围成的面积即为AP 值,公式如下: \[ AP=\sum_{i=1}^{n-1}(Recall_{i+1}-Recall_{i})*Prediction(Recall_{i+1}) \] 本文实验中使用 AP 值衡量网络对每一类物体的检测性能,AP 值越 高代表网络对该类别的检测能力越好;使用 mAP 指示网络对整体数据集的检测 能力,mAP 越高代表网络在此数据集上的表现越好。
4. 实验结果分析
4.1 实验指标结果分析
本文使用上文中的数据集在Yolov5网络上训练300个epoch,最终得到对各个类别的检测性能如下表所示:
| Class | Labels | P | R | mAP@.5 |
|---|---|---|---|---|
| all | 256 | 0.928 | 0.758 | 0.887 |
| hero | 90 | 0.959 | 0.789 | 0.926 |
| grass | 91 | 0.828 | 0.637 | 0.775 |
| dogface | 32 | 0.839 | 0.688 | 0.824 |
| tower | 18 | 0.988 | 0.667 | 0.833 |
| buff | 11 | 1 | 0.916 | 0.995 |
| monster | 12 | 0.997 | 0.667 | 0.851 |
| blood | 1 | 0.935 | 1 | 0.995 |
| dragon | 10 | 0.875 | 0.701 | 0.899 |
模型测试结果如下图所示:
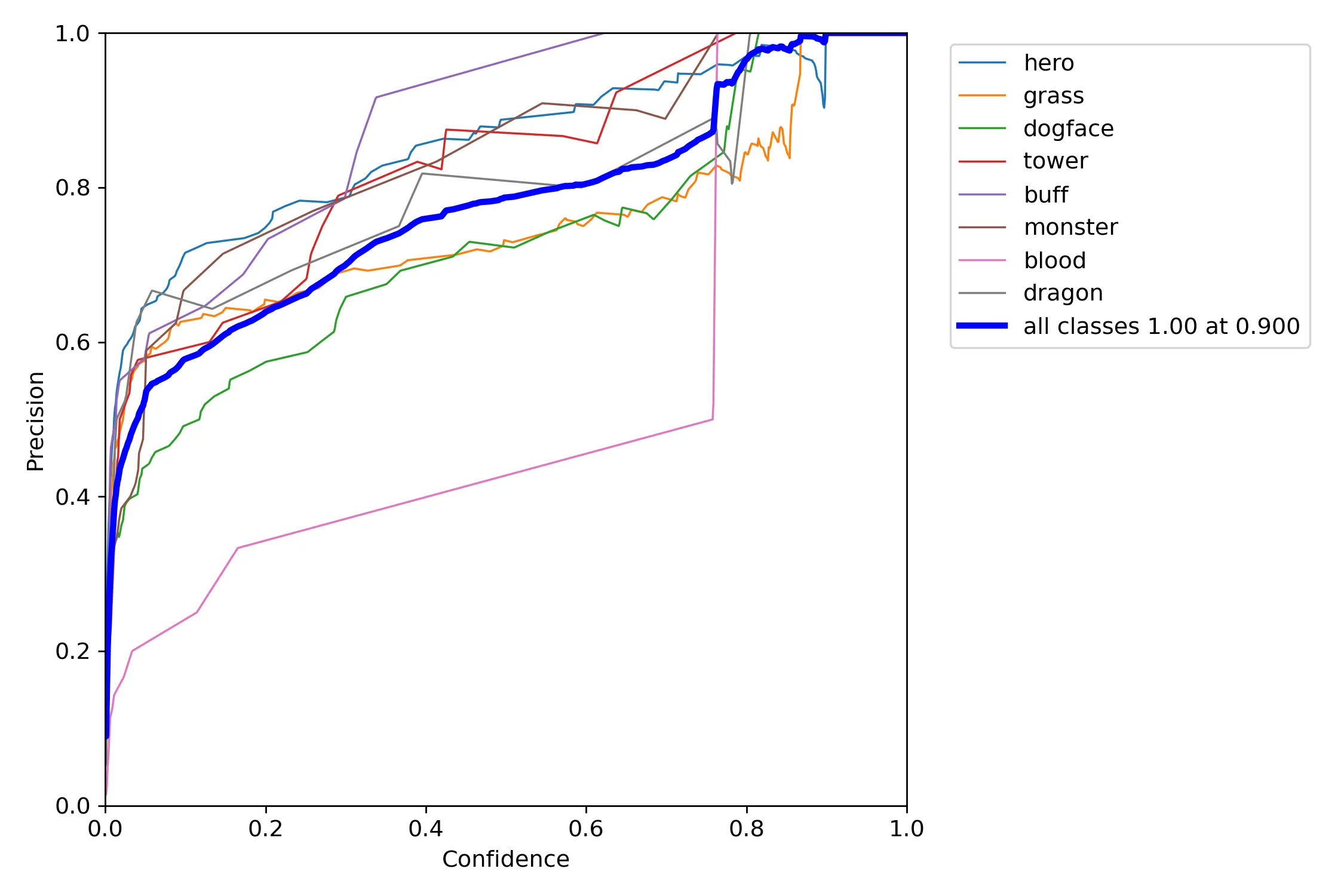
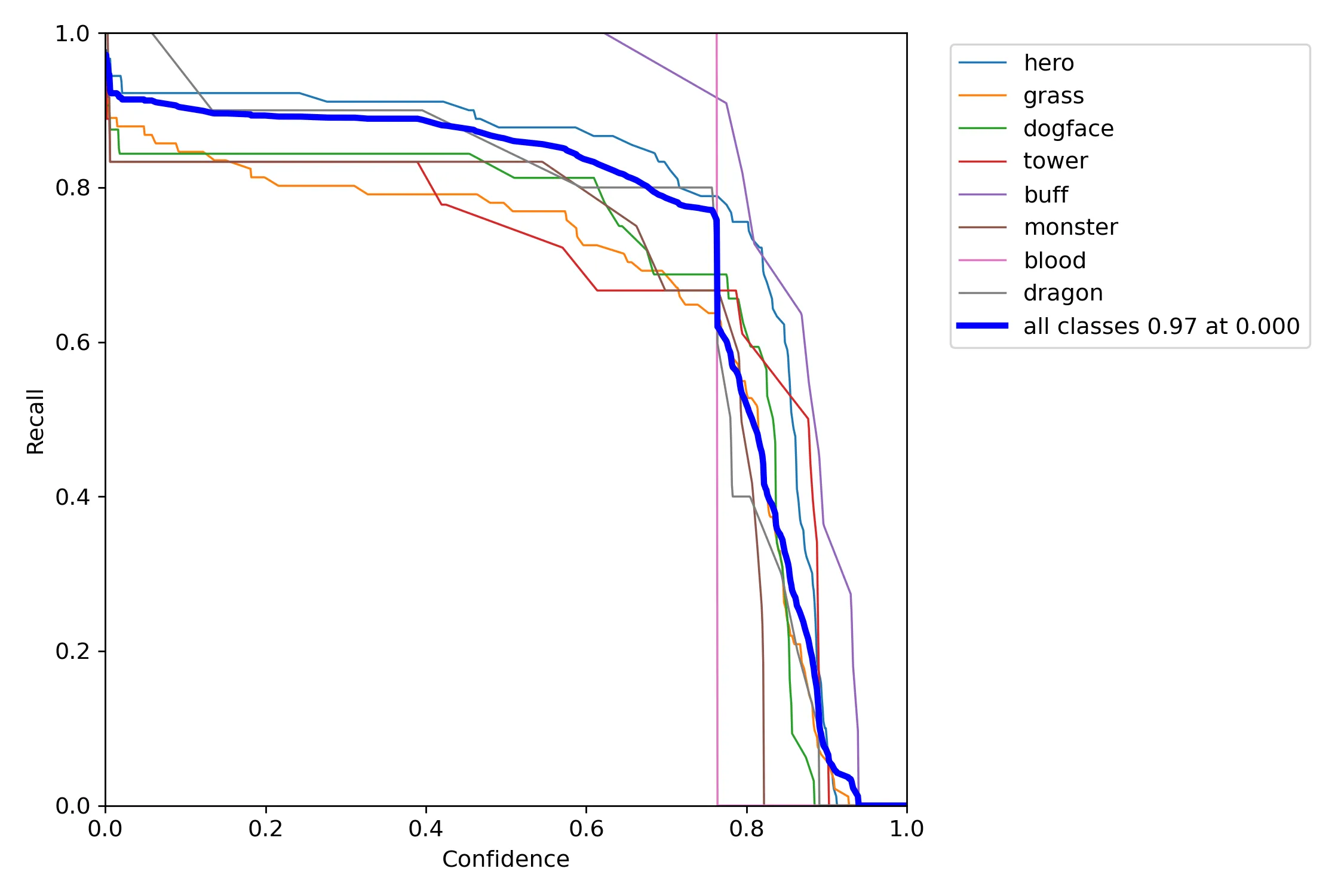

由上述实验结果可以看出,模型的总体检测准确率为92.8%,召回率为75.8%,平均准确率为88.7%。性能表现较好。但在具体类别上的目标检测性能差异较大。具体来说,在英雄,防御塔,红蓝buff,野怪等特征较明显,并且数据量相对较大的主体上的识别能力较好。
此外,从总体上来看,模型的识别准确率较好,而召回率较差。也就是很少将检测目标类型识别错,但并非所有的目标都能够识别出来。结合可视化结果来看,初步推断是由于标记的数据集分布不平稳以及数据量不够充足导致的。后续可以考虑通过补充数据集来提升模型的检测性能。
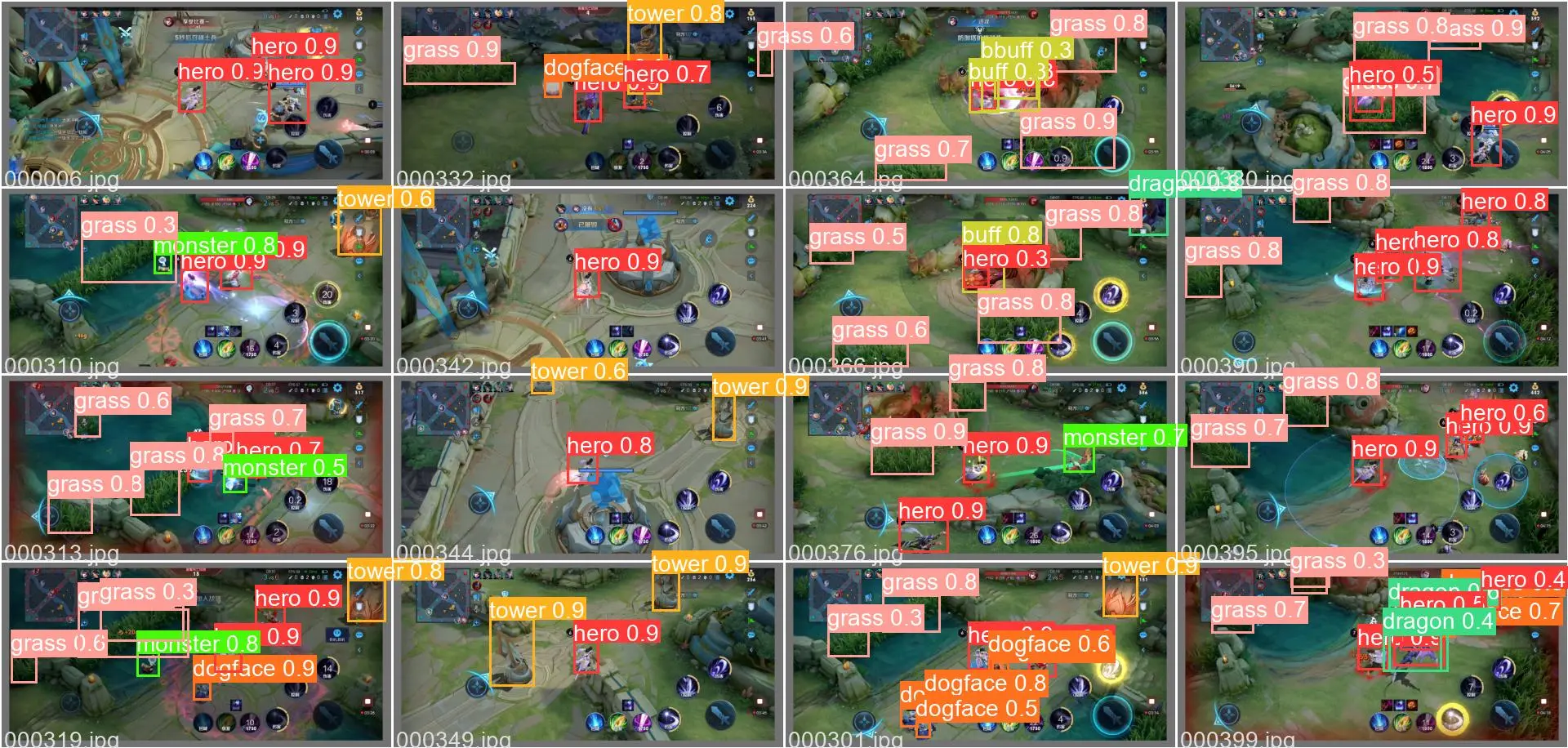
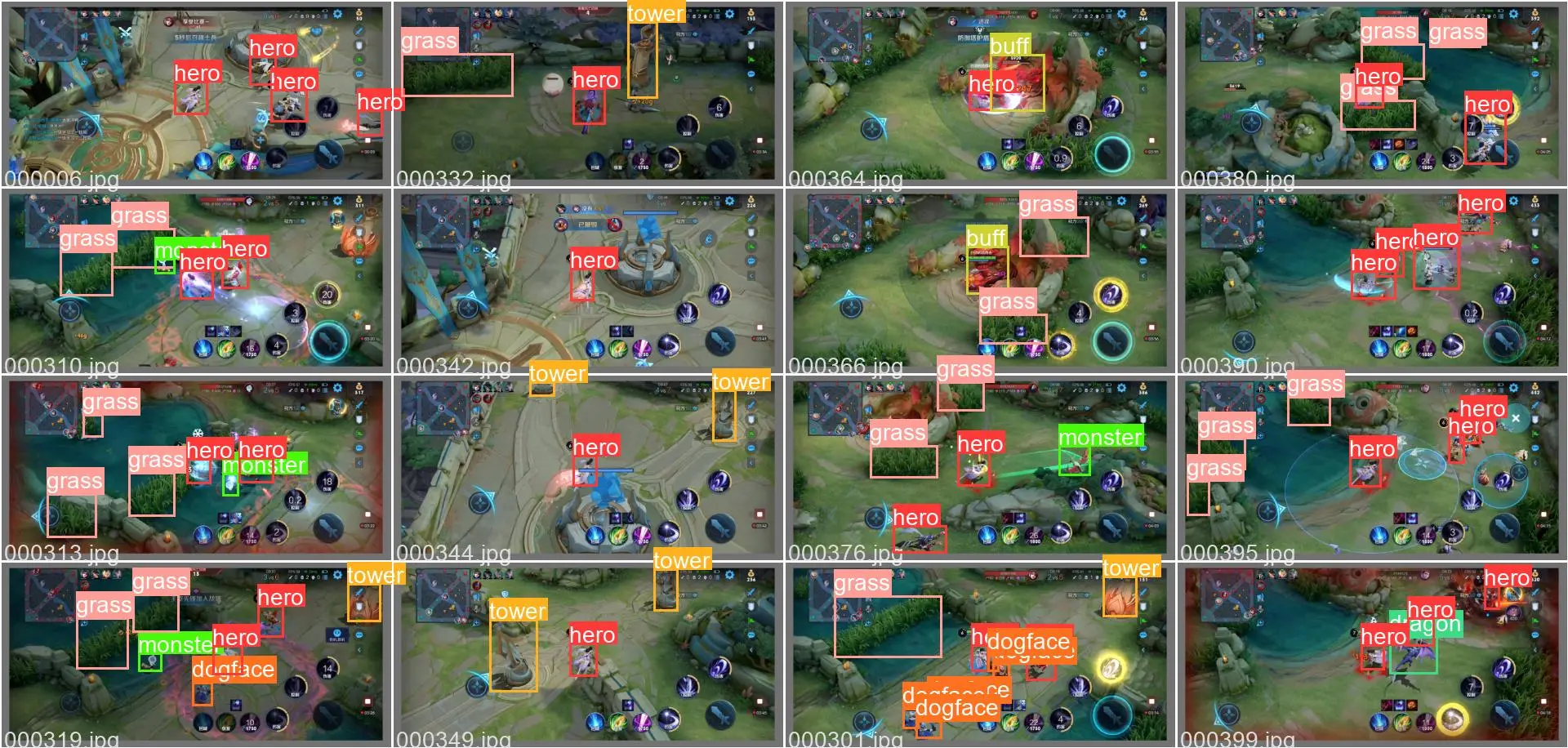
4.2 可视化实验结果
模型在验证集上的部分检测结果和标记数据如下图所示:
此外,本文还将训练好的模型在另一场英雄不同的游戏视频中进行了测试,最终的测试结果视频链接如下:
https://www.bilibili.com/video/BV1Ya411m7mx?share_source=copy_web
从视频中可以看出,虽然本场游戏视频中的英雄未在训练集中出现,但模型依然可以很好的定位和判别出相应主体为英雄类别。说明模型在游戏美术素材上的泛化性能较好,即使对于未曾训练的贴图,也可以很好的判别出相应的主体。
5. 结论
本文使用Yolov5网络构建游戏场景中主体的目标检测,通过图像识别的方式成功对游戏画面中的重要主体进行了定位了判别,使用少量数据训练出的模型最终平均准确率在80%以上。如果可以收集更多的数据,那么最终的检测效果还可以继续提升。而随着目标检测技术的不断发展,图像目标检测的准确率也在不断地提升,检测用时也不断缩短。这为智能体智能决策和作战提供了新的数据处理方法和思考。未来的智能体也许可以基于该技术,主要依靠直接的图像输入而非人工转换数据便可以达到很高的智能水平。
参考文献
- Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M. and Dieleman, S., 2016. Mastering the game of Go with deep neural networks and tree search. nature, 529(7587), pp.484-489.
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T. and Lillicrap, T., 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), pp.1140-1144.
- Vinyals, O., Babuschkin, I., Czarnecki, W.M., Mathieu, M., Dudzik, A., Chung, J., Choi, D.H., Powell, R., Ewalds, T., Georgiev, P. and Oh, J., 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782), pp.350-354.
- Wu, B., 2019, July. Hierarchical macro strategy model for moba game ai. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 1206-1213).
- Ultralytics. (n.d.). Ultralytics. [online] Available at: https://ultralytics.com/yolov5.
- Bochkovskiy, A., Wang, C.Y. and Liao, H.Y.M., 2020. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
附件下载
手动标注数据集及视频分割程序:video2img.zip