King Glory Target Detection - Yolov5 Implementation.
This is an automatically translated post by LLM. The original post is in Chinese. If you find any translation errors, please leave a comment to help me improve the translation. Thanks!
Intelligent Agent for Target Detection in Game Battles
Manual annotation dataset and video segmentation program download can be found at the end of the article.

Demo video:
1. Introduction
1.1 Problem Background
Reinforcement learning has achieved great success in the field of games in the past. For example, AlphaGo defeated human players in the game of Go (Silver, D. et al., 2016), Alpha Zero defeated top human players in various board games after several days of self-play (Silver, D. et al., 2018), and Alpha Star defeated human players in the game StarCraft II (Vinyals, O. et al., 2019). There is also the case of the AI "Juewu" in the game "King of Glory" reaching the level of professional players (Wu, B., 2019). The development of reinforcement learning has led to increasingly better performance of artificial intelligence in game battles.
However, in the problems solved by the above intelligent agents, either the environment is relatively simple (such as board games like Go and chess), or the input to the agent's decision-making process has undergone specific processing. For example, the input to Alpha Star contains a lot of data that cannot be directly observed from the screen (Vinyals, O. et al., 2019). To train a more general intelligent agent, the input to the environment needs to be more general and universal. Computer vision has become a good choice.
In many game battle scenarios, visual information is the most important and information-rich. In games, visual information is the main information that players obtain. In board games, the situation on the board and the opponent's facial expressions are all visual information. In military combat environments, a large number of sensors capture visual-like information. Therefore, it is of great practical significance to convert visual information into environmental description information and send it to the intelligent agent for decision-making.
Among them, target detection is an important part of visual information conversion. Whether in virtual game environments or real environments, it is crucial to identify the terrain, friendly positions, and enemy positions. This is important for the subsequent action decisions of the intelligent agent. Therefore, starting from target detection in game battle scenarios, this article trains a neural network model that can detect enemy and friendly intelligent units, neutral units, and environmental features in the game environment, and achieve the detection of important subjects in the scene.
2. Methodology
In this article, YOLOv5 (Ultralytics) is used to build the target detection network for identifying subjects in game scenes.
The network structure of YOLOv5 is shown in the following figure:
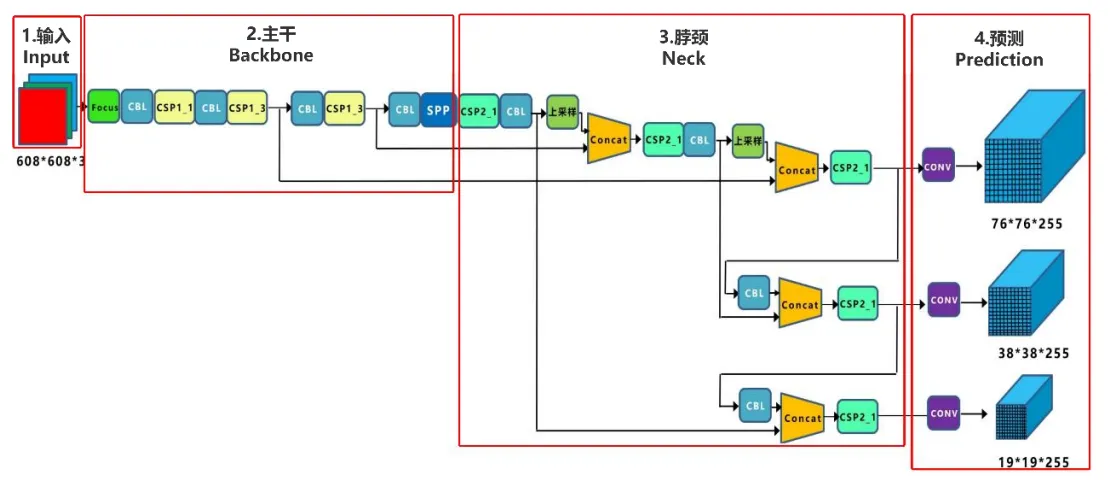
From the network structure diagram of YOLOv5, it can be seen that it is still divided into four parts: Input, Backbone, Neck, and Prediction. Next, we will introduce this network from these four parts.
2.1 Input
YOLOv5 uses the Mosaic data augmentation method, which is the same as YOLOv4. The Mosaic data augmentation method was proposed by a member of the YOLOv5 team. It combines random scaling, random cropping, and random arrangement to splice images together, which works well for detecting small objects.
In the YOLO algorithm, different datasets have anchor boxes with initial settings for width and height. During network training, the network outputs predicted boxes based on the initial anchor boxes, and then compares them with the ground truth boxes to calculate the difference between them, and updates the network parameters in a backward manner. In YOLOv3 and YOLOv4, when training different datasets, the calculation of the initial anchor box values is performed by a separate program. However, YOLOv5 embeds this function into the code, and calculates the optimal anchor box values for different training sets adaptively each time during training.
2.2 Backbone
2.2.1 Focus Structure
The Focus module in YOLOv5 slices the image before it enters the backbone. The specific operation is to take a value every other pixel in an image, similar to nearest neighbor downsampling. In this way, four images are obtained from one image, and these four images complement each other. They have similar sizes but no information loss. In this way, the width and height information is concentrated in the channel space, and the input channels are expanded by 4 times. The concatenated image has 12 channels compared to the original RGB three-channel mode, and then the obtained new image is convolved to obtain a downsampling feature map without information loss. The network structure is as follows:
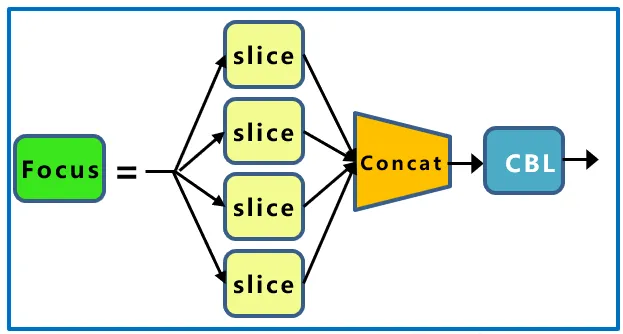
Taking YOLOv5s as an example, the original 640 × 640 × 3 image is input to the Focus structure. After the slicing operation, it becomes a 320 × 320 × 12 feature map, and then it undergoes another convolution operation to finally become a 320 × 320 × 32 feature map. The slicing operation is as follows:

2.2.2 CSP Structure
In the YOLOv4 network structure, the design idea of CSPNet is borrowed, and the CSP structure is designed in the backbone network. The difference between YOLOv5 and YOLOv4 is that only the backbone network uses the CSP structure in YOLOv4. In YOLOv5, two CSP structures are designed. Taking the YOLOv5s network as an example, the CSP1_X structure is applied to the backbone network, and the other CSP2_X structure is applied to the Neck. The network structure is as follows:
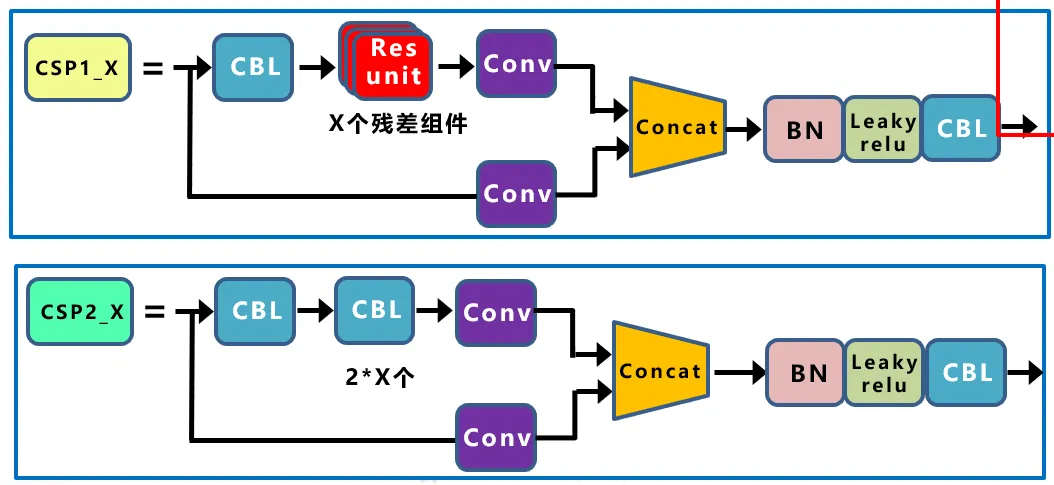
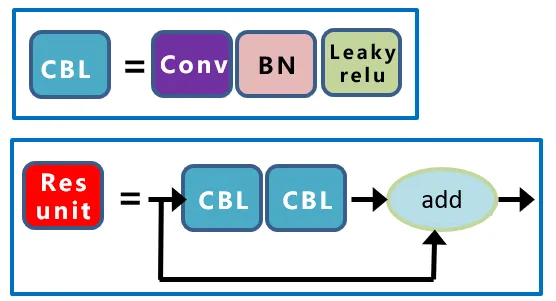
The CBL structure and Resunit structure are shown in the following figure:
2.2.3 SPP Structure
The SPP module is inspired by SPPNet (Spatial Pyramid Pooling Network) and consists of four parallel branches. It uses convolution with multiple different-sized kernels to convolve the image and then merges the convolution results. This effectively expands the receptive field of the model, allowing the model to handle images with large differences in size. The network structure is as follows:
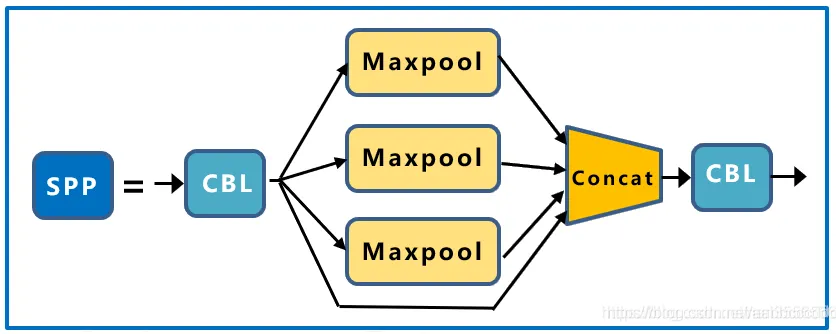
2.3 Neck
The Neck part of YOLOv5 uses the PANet structure, which is mainly used to generate a feature pyramid. The feature pyramid enhances the model's detection of objects at different scales, allowing it to recognize the same object of different sizes and scales.
The PANet structure is based on FPN and introduces the Bottom-up path augmentation structure. FPN mainly improves the effect of object detection by fusing high-level and low-level features, especially improving the detection effect of small objects. The Bottom-up path augmentation structure can make full use of shallow features in the network for segmentation. Shallow features are very important for object detection because object detection is a pixel-level classification, and shallow features are mostly edge shape features. PANet adds an enhancement in the bottom-up direction based on FPN, allowing the top-level feature map to also benefit from the rich position information brought by the bottom-level feature map, thereby improving the detection effect of large objects.
In addition, YOLOv5's Neck structure uses the CSP2 structure designed based on CSPnet to enhance the network's feature fusion capability.
2.4 Prediction
2.4.1 Bounding Box Loss Function
YOLOv5 uses GIOU Loss as the bounding box loss function. GIOU not only focuses on the overlapping area but also considers other non-overlapping areas, which better reflects the degree of overlap between the two.
2.4.2 Weighted Non-Maximum Suppression (NMS)
In the post-processing of object detection, NMS is usually required for filtering many bounding boxes. YOLOv5 uses weighted NMS to remove bounding boxes. Compared with traditional non-maximum suppression, weighted non-maximum suppression does not directly compare the bounding boxes with a threshold for filtering. Instead, it calculates the final object detection bounding box based on the confidence of the network's prediction results.
3. Dataset and Evaluation Metrics
3.1 Dataset Preparation
In this article, a manually annotated game screen dataset is used. The game screens are obtained by randomly sampling frames from a match of the game "King of Glory". A total of 8 classes of subjects are annotated, and their categories and labels are shown in the following table:
| Category | Hero | Dogface | Monster | Tower | Grass | Dragon | Buff | Blood |
|---|---|---|---|---|---|---|---|---|
| Label | hero | dogface | monster | tower | grass | dragon | buff | blood |
The number of annotated samples for each category is shown in the following table:
| Category | Hero | Dogface | Monster | Tower | Grass | Dragon | Buff | Blood |
|---|---|---|---|---|---|---|---|---|
| Training | 319 | 101 | 83 | 58 | 353 | 48 | 30 | 6 |
| Validation | 90 | 32 | 12 | 18 | 91 | 10 | 11 | 1 |
3.2 Evaluation Metrics
The evaluation metrics of the model mainly consist of two parts: precision and recall. Specifically: \[ Precision = \frac{TP}{TP+TN}\\ Recall = \frac{TP}{TP+FP} \] In object detection, the average precision (AP) of each category is usually used to measure the performance of the algorithm. Its value is determined by both precision and recall. The precision and recall calculated by the formula can be used to draw a precision-recall (P-R) curve, and the area enclosed by the curve and the X-axis is the AP value. The formula is as follows: \[ AP = \sum_{i=1}^{n-1}(Recall_{i+1}-Recall_{i})*Precision(Recall_{i+1}) \] In this article, the AP value is used to measure the detection performance of the network for each category of objects, and the mAP value indicates the overall detection performance of the network on this dataset.
4. Experimental Results Analysis
4.1 Analysis of Experimental Metrics Results
In this article, the YOLOv5 network is trained for 300 epochs on the dataset mentioned above, and the final detection performance for each category is shown in the following table:
| Class | Labels | P | R | mAP@.5 |
|---|---|---|---|---|
| all | 256 | 0.928 | 0.758 | 0.887 |
| hero | 90 | 0.959 | 0.789 | 0.926 |
| grass | 91 | 0.828 | 0.637 | 0.775 |
| dogface | 32 | 0.839 | 0.688 | 0.824 |
| tower | 18 | 0.988 | 0.667 | 0.833 |
| buff | 11 | 1 | 0.916 | 0.995 |
| monster | 12 | 0.997 | 0.667 | 0.851 |
| blood | 1 | 0.935 | 1 | 0.995 |
| dragon | 10 | 0.875 | 0.701 | 0.899 |
The model's test results are shown in the following figures:
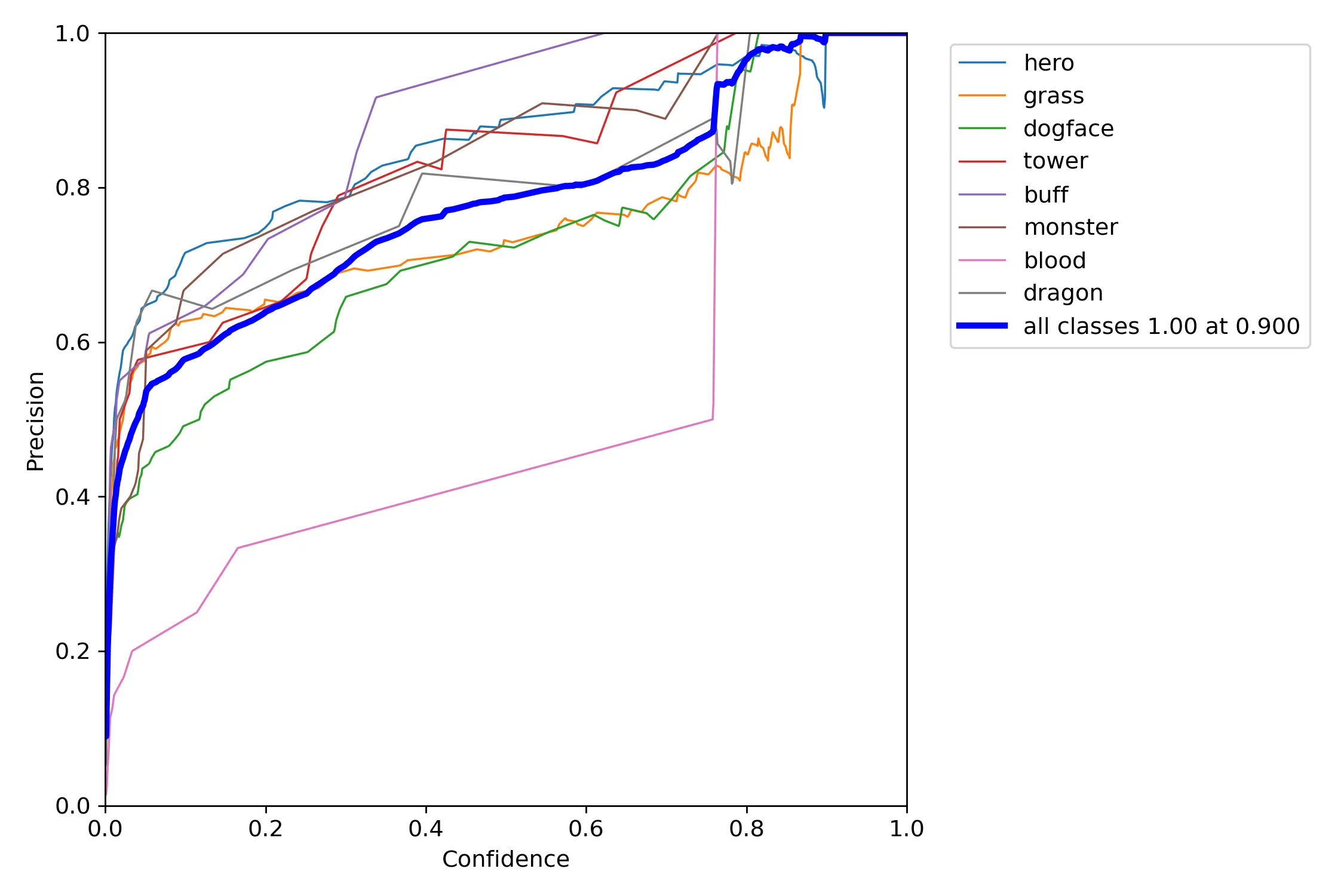
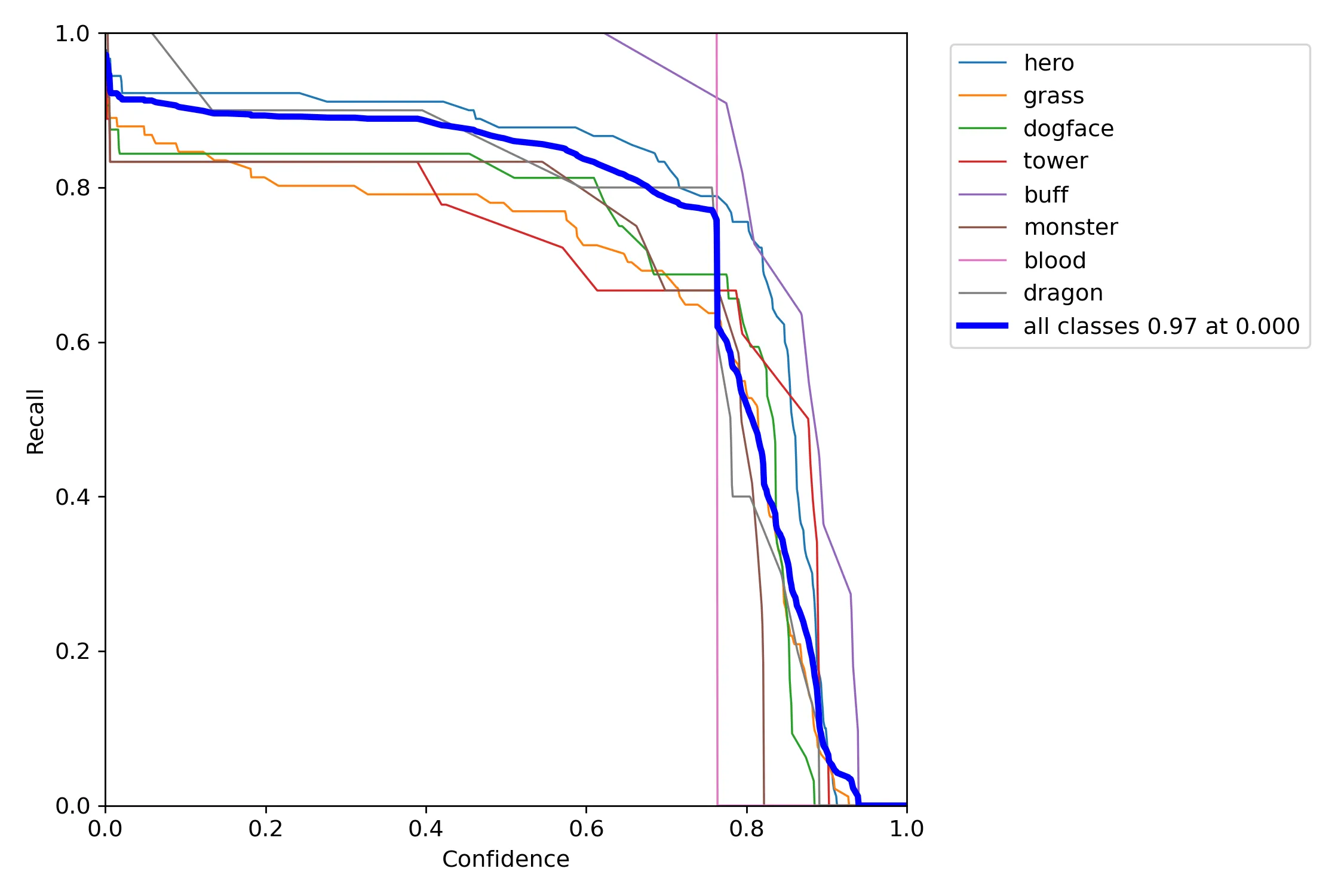

From the above experimental results, it can be seen that the overall detection accuracy of the model is 92.8%, the recall rate is 75.8%, and the average precision is 88.7%. The performance is good. However, there are significant differences in the target detection performance among specific categories. Specifically, the recognition ability is better for subjects with more obvious features and relatively large amounts of data, such as heroes, towers, red and blue buffs, and monsters.
In addition, overall, the model has good recognition accuracy but poor recall. That is, it rarely misidentifies the types of detected targets, but not all targets can be recognized. Combining the visual results, it is initially inferred that this is due to the uneven distribution of the annotated dataset and insufficient data. In the future, it is possible to improve the detection performance of the model by supplementing the dataset.
4.2 Visualization of Experimental Results
Some detection results and annotated data on the validation set are shown in the following figures:
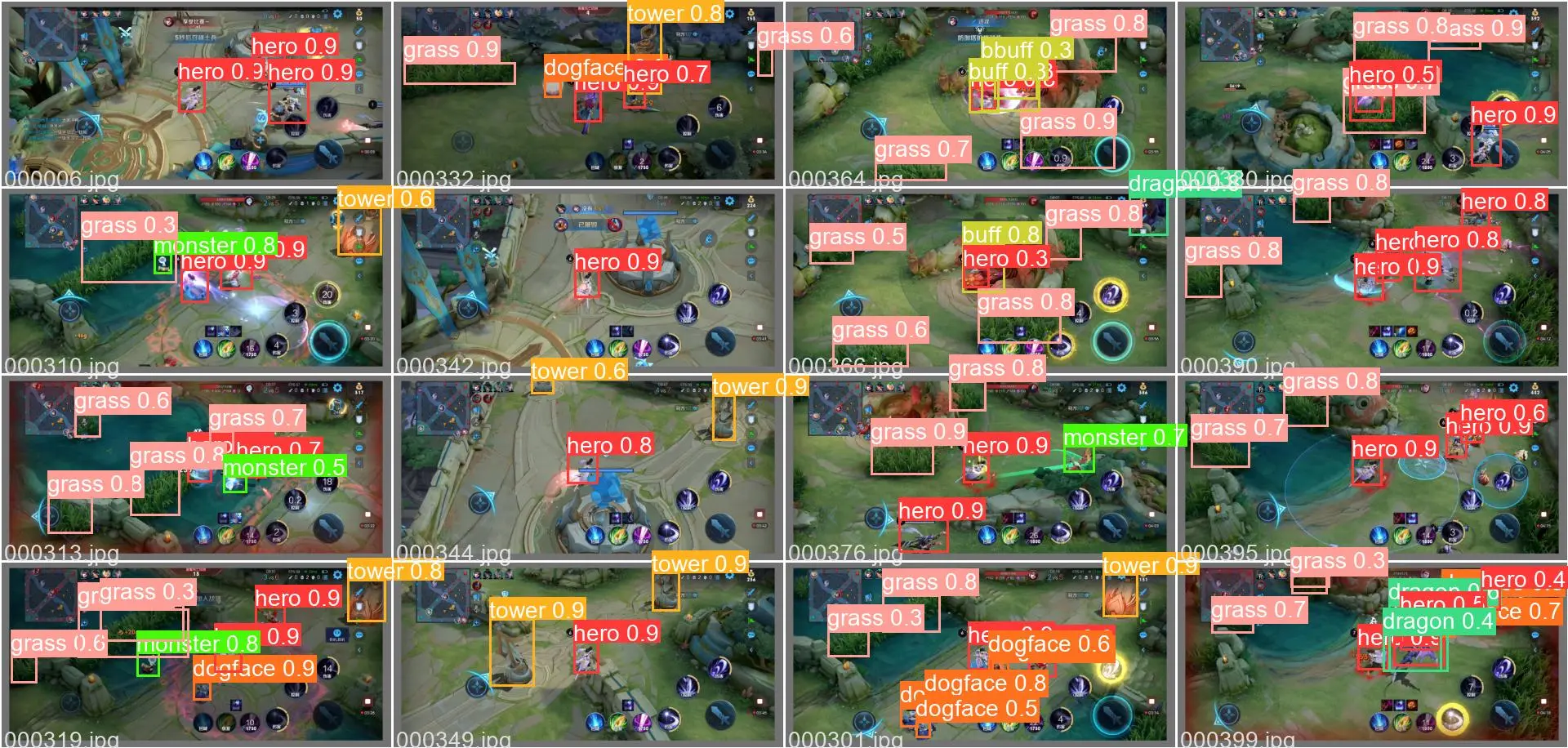
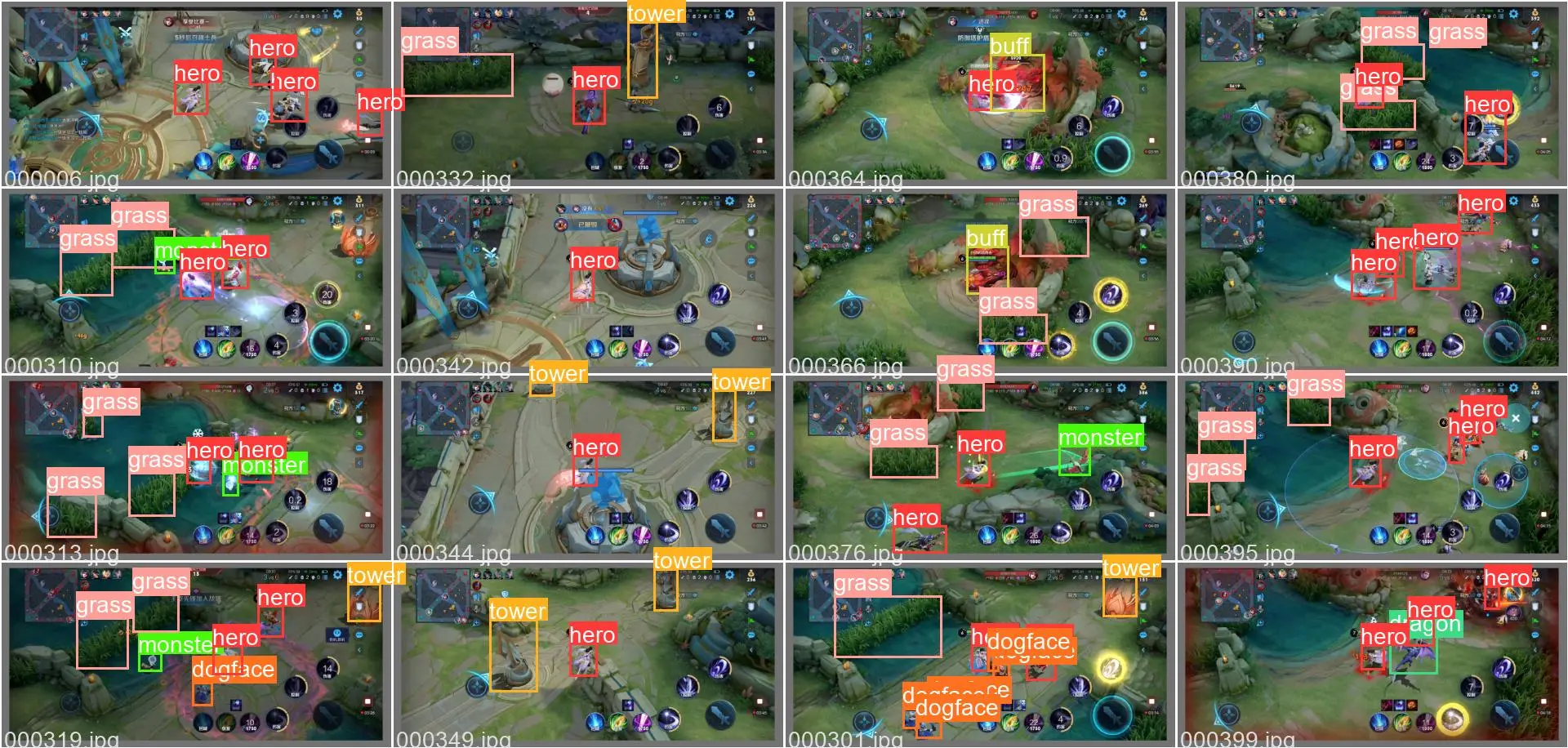
In addition, the trained model was tested on a different game video with different heroes, and the final test result video link is as follows:
https://www.bilibili.com/video/BV1Ya411m7mx?share_source=copy_web
From the video, it can be seen that although the heroes in this game video did not appear in the training set, the model can still locate and identify the corresponding subjects as hero category. This indicates that the model has good generalization performance on game art materials, and it can recognize the corresponding subjects even for textures that have not been trained.
5. Conclusion
In this article, the YOLOv5 network is used to build target detection in game scenes. The important subjects in the game screens are successfully located and identified through image recognition. The model trained with a small amount of data achieves an average precision of over 80%. If more data can be collected, the final detection performance can be further improved. With the continuous development of target detection technology, the accuracy of image object detection is constantly improving, and the detection time is also getting shorter. This provides new data processing methods and ideas for intelligent decision-making and combat of intelligent agents. In the future, intelligent agents may be able to achieve high levels of intelligence based on this technology, mainly relying on direct image input rather than manually converted data.
References
- Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M. and Dieleman, S., 2016. Mastering the game of Go with deep neural networks and tree search. nature, 529(7587), pp.484-489.
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T. and Lillicrap, T., 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), pp.1140-1144.
- Vinyals, O., Babuschkin, I., Czarnecki, W.M., Mathieu, M., Dudzik, A., Chung, J., Choi, D.H., Powell, R., Ewalds, T., Georgiev, P. and Oh, J., 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782), pp.350-354.
- Wu, B., 2019, July. Hierarchical macro strategy model for moba game ai. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 1206-1213).
- Ultralytics. (n.d.). Ultralytics. [online] Available at: https://ultralytics.com/yolov5.
- Bochkovskiy, A., Wang, C.Y. and Liao, H.Y.M., 2020. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
Appendix Download
Manual annotation dataset and video segmentation program: video2img.zip