Tips for Constructing Pytorch Networks
This is an automatically translated post by LLM. The original post is in Chinese. If you find any translation errors, please leave a comment to help me improve the translation. Thanks!
About Network Parameters
In Pytorch, each network inherits from the nn.Module
class and implements various network functions by maintaining the
following eight dictionaries after instantiation:
1 | _parameters |
During the network initialization process __init__, the
definition of all class variables is registered in __dict__
through the __setattr__ method. nn.Module
overrides the registration method and assigns all variables derived from
the Parameter type in the class to the
_parameters dictionary. This explains why using a
list to store each layer of the network will result in
empty parameters.
In addition, when obtaining parameters, nn.Module
traverses the entire _modules dictionary. Therefore,
nn.ModuleList can be used instead of list to
store multiple network layers.
Modifying an Instantiated Network
When obtaining a pre-trained model from others, it is sometimes necessary to modify the network, such as resetting parameters or replacing certain modules in the network for retraining. One direct approach is to find the corresponding attribute in the class and directly assign and replace it.
First, to modify parameters, there are two approaches. Since
modifying parameters does not change the network structure, the network
parameter dictionary and import method provided by pytorch
can be used directly:
1 | state_dict = model.state_dict() |
Another approach is to use named_parameters() to perform
corresponding modifications:
1 | for name, params in model.named_parameters(): |
The above are the methods for modifying parameters. Relatively
speaking, modifying parameters is relatively simple, and
pytorch also provides some methods for convenient parameter
replacement. As for modifying the model, the implementation approach is
more direct. Find the location of the layer in the model
and replace it. named_modules() method is used here. Taking
the open-source large language model llama-2-13b as an
example, after the model is loaded, first check the names of each
layer:
1 | for name,layer in model.named_modules(): |
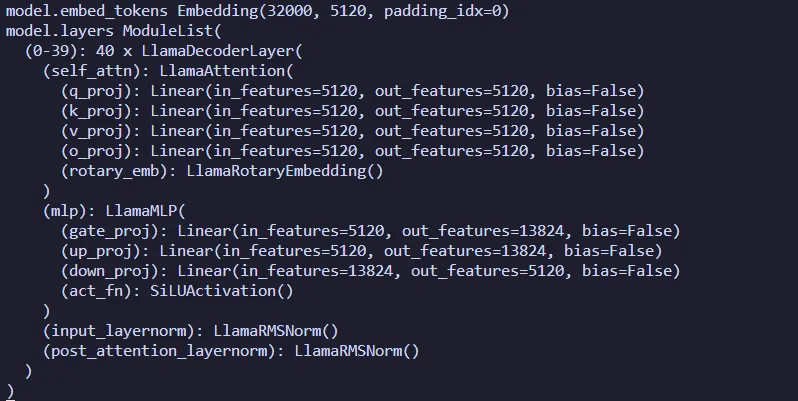
Then find the name of the layer that needs to be replaced and replace
it. Taking the embeding layer as an example:
1 | from torch import nn |
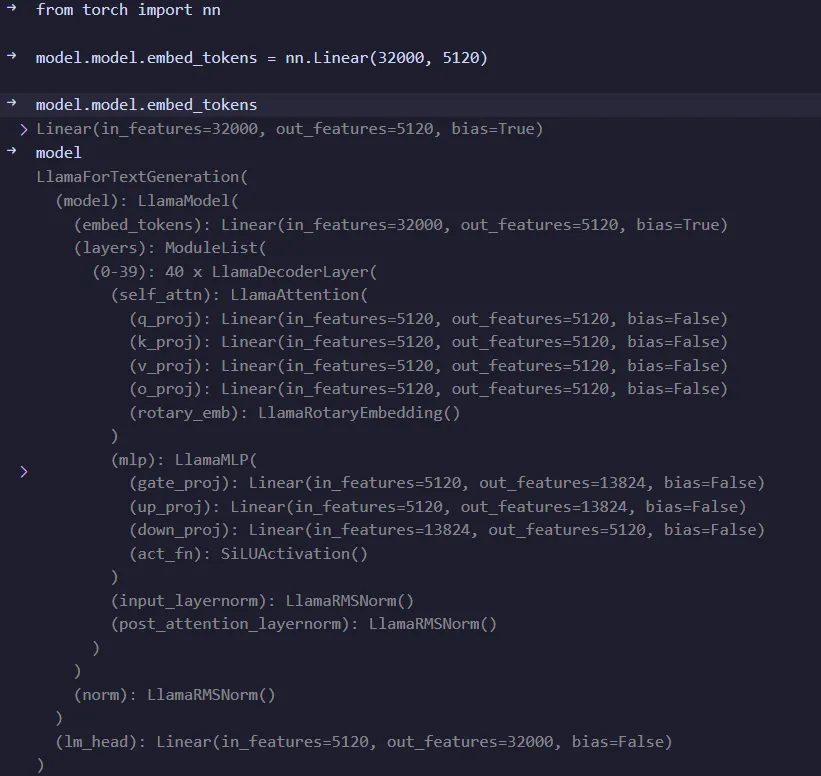
It can be seen that the embedding layer has been
successfully replaced with a fully connected layer. Modifications to
other layers follow suit.
Reference
[1] Gemfield, "Detailed Explanation of Network Construction in Pytorch," Zhihu Column, Jan. 04, 2019. https://zhuanlan.zhihu.com/p/53927068 (accessed Sep. 26, 2022).