Terminated and Truncated in reinforcement learning.
This is an automatically translated post by LLM. The original post is in Chinese. If you find any translation errors, please leave a comment to help me improve the translation. Thanks!
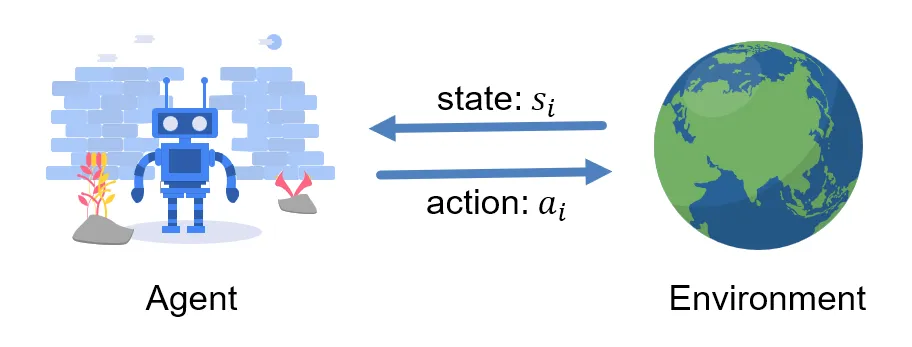
The process of deep reinforcement learning can be abstracted into the following steps:
- The agent interacts with the environment and generates and stores experiences.
- The agent learns from the experiences.
This article mainly discusses the impact of natural termination (Terminated), including successful or failed goals, and artificial truncation (Truncated), mainly ending after a certain number of steps, on experience collection and training. It also conducts some experiments to compare performance.
Introduction to Q-Learning
In the Q-Learning series of algorithms, the agent learns to estimate the optimal Q-value \(Q^{*}(s,a)\) for each action under each state \(s\). The Bellman equation is as follows: \[ Q^*(s_t,a_t)=r_t+\gamma \cdot \max_{a'\in A(s_{t+1})}Q^*(s_{t+1},a_{t+1}) \] When \(s_{t+1}\) is a terminal state, i.e., \(done(s_{t+1})=True\), the equation becomes: \[ Q^*(s_t,a_t)=r_t \]
Combined together, it can be written as: \[ Q^*(s_t,a_t)=\left\{ \begin{array}{**lr**} r_t+\gamma \cdot \max_{a'\in A(s_{t+1})}Q^*(s_{t+1},a_{t+1}) & \text{if } done(s_{t+1})=False\\ r_t & \text{if } done(s_{t+1})=True \end{array} \right. \] In the implementation of the program, it is usually written as:
1 | q_target = reward + self._gamma * max_next_q_value * (1 - done) |
Truncation Issue
The key to Q-Learning is the accurate estimation of the value function. If the environment is artificially truncated during the deduction process and treated as a termination, the estimation of \(Q^*\) will lack the term \(\gamma \cdot \max_{a'\in A(s_{t+1})}Q^*(s_{t+1},a_{t+1})\). This can make the \(Q^*\) function unstable or difficult to converge during the learning process. Additionally, the terminal state is often related to the reward \(r_t\). If the truncation situation is not handled separately, it may give the agent a biased reward, resulting in problems during the training process.
Therefore, when recording experiences and designing rewards, in
addition to considering natural termination (Terminated), one should
also consider artificial truncation (Truncated). The reinforcement
learning environment library gym has included these two
pieces of information in each step since version 0.26, making training
more convenient.
Considering the truncation, the Bellman equation for \(Q^*\) in the program implementation becomes:
1 | q_target = reward + self._gamma * max_next_q_value * (1 - done + truncated) |
Experimental Comparison
This article conducted tests on the CartPole-v1
environment in gym. The maximum number of episodes was set
to 200, the number of training steps was 500, the hidden layer network
was a fully connected network with 2 layers and 64 nodes, the training
was performed 8 times per step, the buffer size was 100,000, the batch
size was 64, the minimum training experience was 500, the initial \(\epsilon\) was 0.9, the terminal \(\epsilon\) was 0.01, and the \(\epsilon\) decay step was 200 steps. The
reward function was defined as follows:
1 | def cart_pole_v1(params): |
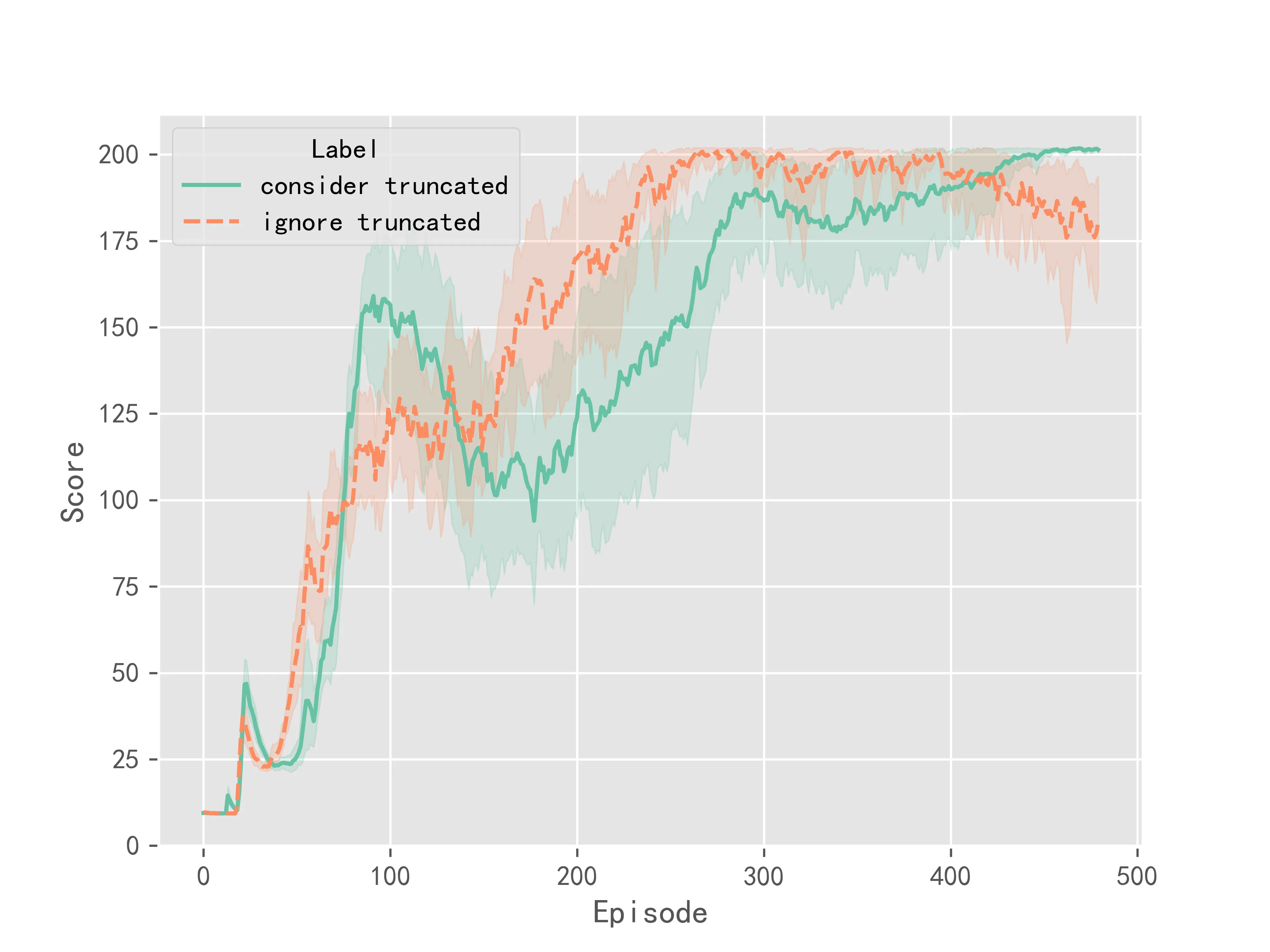
The experimental results for the DQN algorithm are shown in Figure 1:
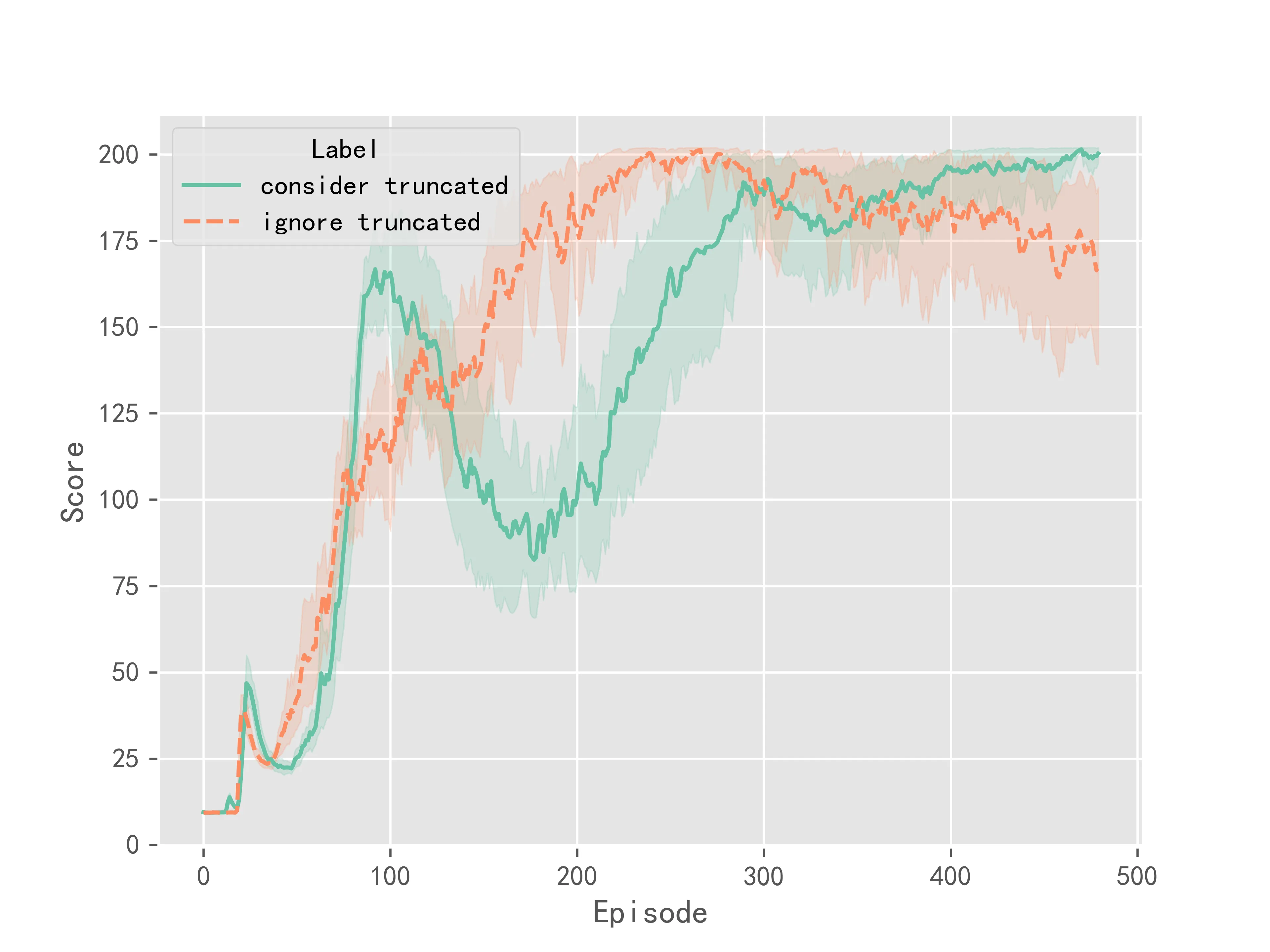
The experimental results for the Double DQN algorithm are shown in Figure 2:
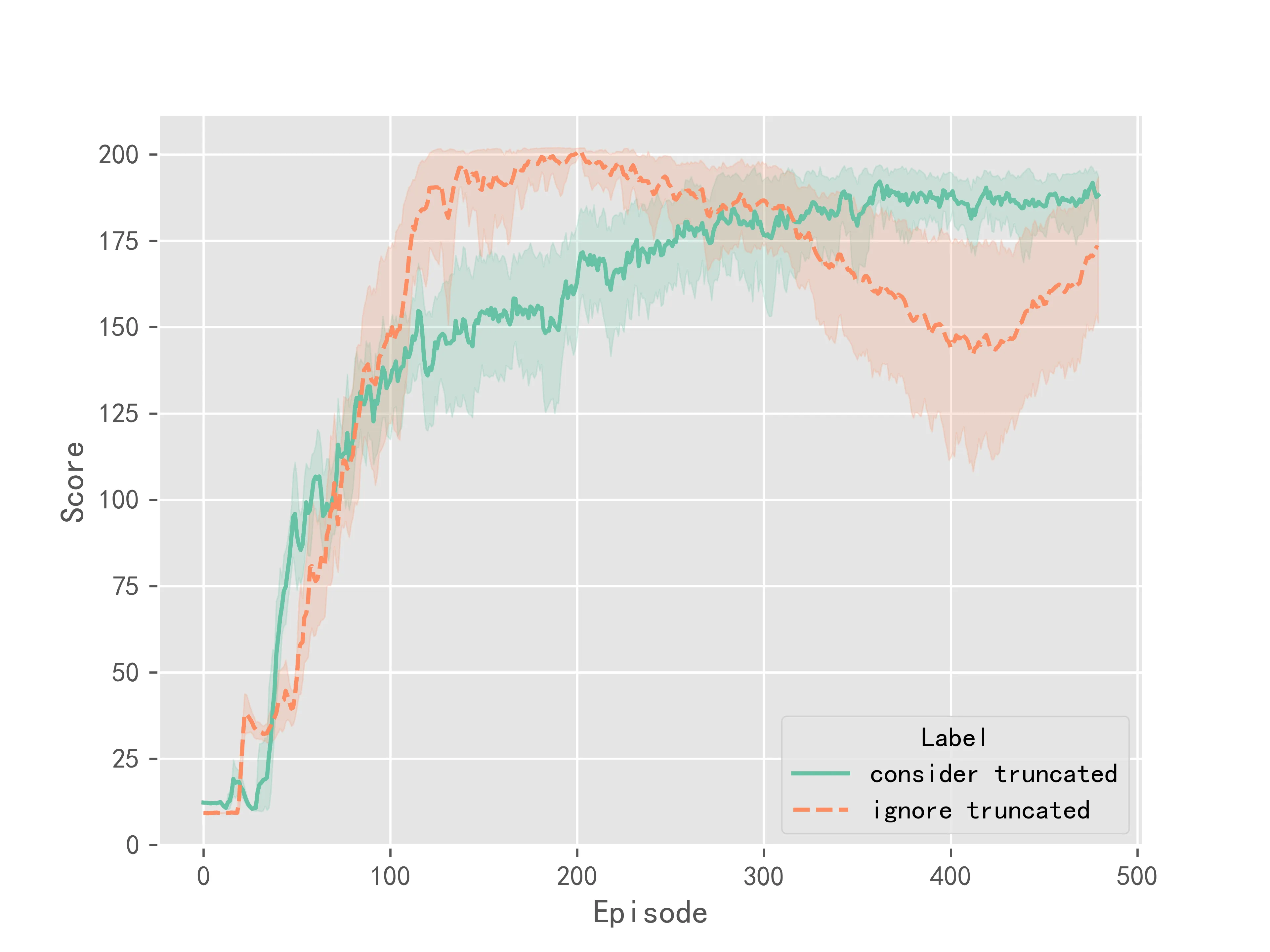
The experimental results for the Dueling DQN algorithm are shown in Figure 3:
The experimental results for the D3QN algorithm are shown in Figure 4:
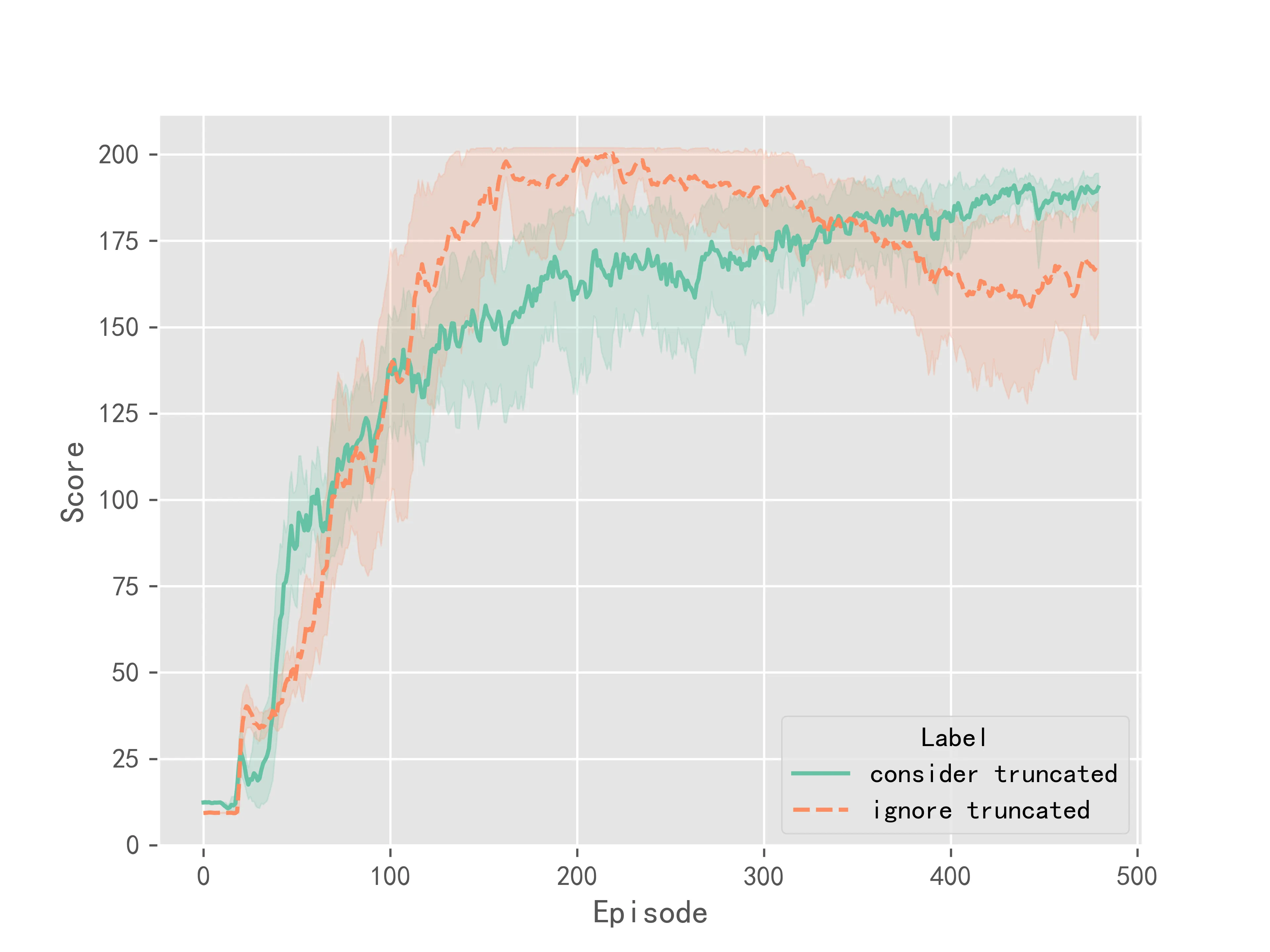
The above experimental results indicate that considering truncation makes the training of the algorithm more stable, resulting in smaller variance in the final convergence. However, considering truncation does not significantly improve the convergence speed or performance of the Q-Learning series of algorithms. It mainly improves the stability during training.