Nlp工具Nltk的安装及使用
This is an automatically translated post by LLM. The original post is in Chinese. If you find any translation errors, please leave a comment to help me improve the translation. Thanks!
Introduction to NLTK
NLTK is a leading platform for building Python programs that use human language data. It provides an easy-to-use interface for over 50 corpora and lexical resources (such as WordNet), as well as a text processing library for classification, tokenization, stemming, tagging, parsing, and semantic inference. NLTK is a famous natural language processing library on Python, which comes with its own corpus, part-of-speech tagging library, tokenization, and other functions.
Package Installation
First, install the NLTK package using pip:
1 | pip install nltk |
You can use the Tsinghua source to speed up the installation:
1 | pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple |
Downloading NLTK Data
After installing the NLTK package, you need to download the relevant data models to use it. The download method is as follows.
After installing the NLTK package, open the Python command line and run the following command (you can also create a new Python file and write the following command to run it):
1 | import nltk |
The following interface will appear:
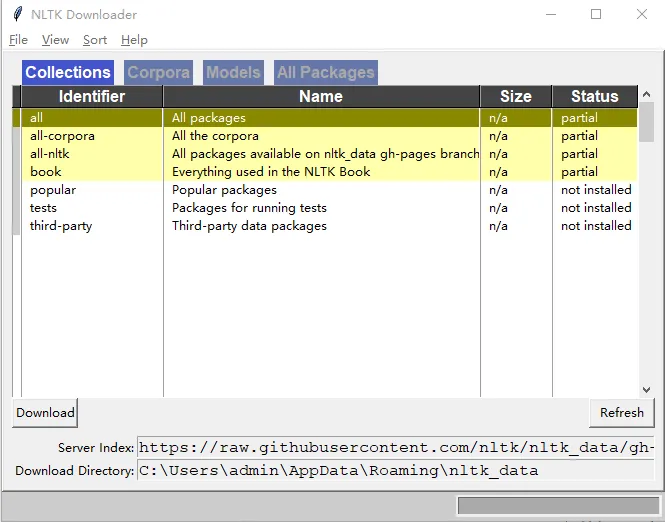
At first, this list is blank. Click "refresh" in the lower right corner to display the nltk-data list.
Click "Download" in the lower left corner to start downloading the data. After the download is complete, you can use it normally.
Accelerated Download in China
When downloading in China, you may encounter situations where DNS cannot be found or errors occur during the download. The most convenient solution when encountering this situation is as follows:
Execute one of the following commands to download nltk-data to the local machine, which is about 700M in size:
1
2
3
4git clone https://github.com/nltk/nltk_data.git
# If you cannot connect to GitHub, you can also use one of the following links to clone
git clone http://gitclone.com/github.com/nltk/nltk_data.git
git clone https://hub.fastgit.org/nltk/nltk_data.gitEnter the nltk-data directory downloaded to the local machine, and modify the index.xml file under the nltk_data directory, replacing all
1
s://raw.githubusercontent.com/nltk/nltk_data/gh-pages
with:
1
://localhost:8000
Run the following command in this directory:
1
python -m http.server 8000
At this time, we will provide a server that provides nltk_data data download services on our local machine. The nltk downloader can obtain the required files by accessing the local address.
Re-execute the following statement in Python:
1
2import nltk
nltk.download()Replace the address in the server index with
http://localhost:8000/index.xmlas shown in the figure below: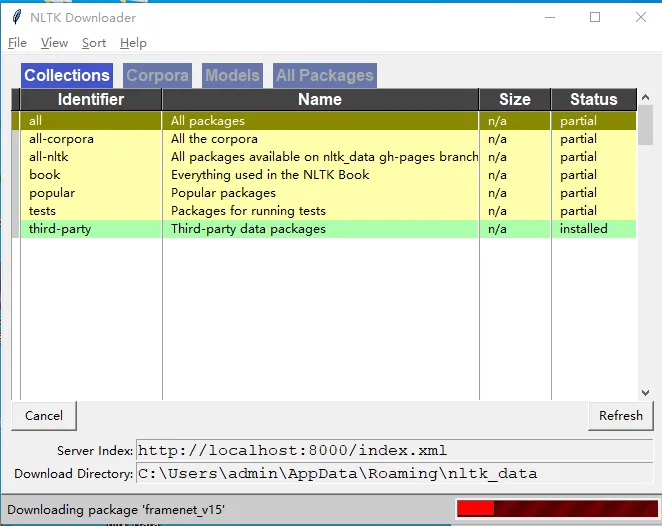
Click "refresh" and "Download" in turn to start the installation.
Reference
[1] 国内下载GITHUB库加速方法及快速安装NLTK - 知乎 (zhihu.com)
[2] 直接快速下载NLTK数据_今春一别难相逢-CSDN博客_nltk下载